




- @weixin_43827285
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着大语言模型(LLMs)与多模态视觉-语言模型(VLMs)在数字世界的认知能力趋于成熟,人工智能的触角正不可阻挡地向物理世界延伸。近年来,具身智能基础模型(Embodied Foundation Models)在复杂语义理解、常识推理与通用任务规划方面取得了突破性进展。然而,当试图将基于单一或局部本体数据训练的控制策略,零样本(Zero-shot)或少样本(Few-shot)迁移到具备不同硬件拓
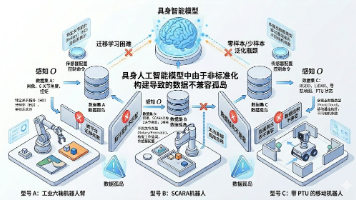
随着大语言模型(LLMs)与多模态视觉-语言模型(VLMs)在数字世界的认知能力趋于成熟,人工智能的触角正不可阻挡地向物理世界延伸。近年来,具身智能基础模型(Embodied Foundation Models)在复杂语义理解、常识推理与通用任务规划方面取得了突破性进展。然而,当试图将基于单一或局部本体数据训练的控制策略,零样本(Zero-shot)或少样本(Few-shot)迁移到具备不同硬件拓
随着大语言模型(LLMs)与多模态视觉-语言模型(VLMs)在数字世界的认知能力趋于成熟,人工智能的触角正不可阻挡地向物理世界延伸。近年来,具身智能基础模型(Embodied Foundation Models)在复杂语义理解、常识推理与通用任务规划方面取得了突破性进展。然而,当试图将基于单一或局部本体数据训练的控制策略,零样本(Zero-shot)或少样本(Few-shot)迁移到具备不同硬件拓
现有的VLA(Vision-Language-Action )模型具有这些局限性:1)大多封闭且开放;2)未能探索高效地为新任务微调VLA的方法,而这是VLAs被采用的关键组成部分。为此本工作开发了OpenVLA,一个基于97万条Open X-Embodiment机器人任务的7B参数开源VLA模型,它为通用机器人操作策略设定了新的技术前沿,它支持直接控制多台机器人,并且可以通过参数高效微调快速适应

Real-Time Plane Segmentation using RGB-D Cameras:改论文是基于depth图像做的平面检测, 根据depth得到的三维点, 根据三维点所在邻域平面法向量以及平面距原点的距离,对其进行聚类, 具体流程如下:利用depth点上下左右的点,计算出该点邻域平面的法向量;将所有的点根据上述求出来的三维法向量, 分配到三维的voxel grid里去, 这也就是第一
现有的VLA(Vision-Language-Action )模型具有这些局限性:1)大多封闭且开放;2)未能探索高效地为新任务微调VLA的方法,而这是VLAs被采用的关键组成部分。为此本工作开发了OpenVLA,一个基于97万条Open X-Embodiment机器人任务的7B参数开源VLA模型,它为通用机器人操作策略设定了新的技术前沿,它支持直接控制多台机器人,并且可以通过参数高效微调快速适应

DWA/DWB采样时,采样速度会倾向于目标速度,这使得速度只会单调变化(如单调减少,或者单调增加),对于线速度而言没什么明显不合适,但对于旋转而言,则造成每条采样轨迹只能朝一个方向延伸,如下图所示(黑色表示不合理采样轨迹,绿色无箭头附着的表示合理轨迹,绿色有箭头附着的为想跟随的参考轨迹),不适用于Z字形连续弯道和需要频繁转向的动态避障,这也是一个值得优化的点。有点则在于算法简单高效,低动态场景下适

现有的VLA(Vision-Language-Action )模型具有这些局限性:1)大多封闭且开放;2)未能探索高效地为新任务微调VLA的方法,而这是VLAs被采用的关键组成部分。为此本工作开发了OpenVLA,一个基于97万条Open X-Embodiment机器人任务的7B参数开源VLA模型,它为通用机器人操作策略设定了新的技术前沿,它支持直接控制多台机器人,并且可以通过参数高效微调快速适应
VINS-FUSION源码框架及C++知识点总结VINS-FUSION程序架构前端 VINS-FUSION是港科大空中机器人实验室的开源视觉惯性导航SLAM,在此称为slam,是因为不同于VIO,它具有回环和地图复用功能,是一个完整的基于优化算法的slam系统,有关该算法介绍及其中的数学理论部分见之后的链接,在此不再讲解,而是专注于其代码实现的过程.VINS-FUSION githubVI...