




- @weixin_43738866
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
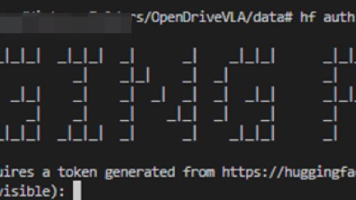
OpenDriveVLA 是当前自动驾驶领域最受关注的视觉语言动作(Vision-Language-Action)模型之一,基于 Qwen2.5 系列大模型构建,能够直接从多模态输入(图像、文本指令)输出端到端的驾驶轨迹。本文将带你从零完成 OpenDriveVLA 的环境部署与推理验证,重点解决国内模型下载受限、分布式启动报错等问题。国内下载模型必须配置HF_ENDPOINT=https://h
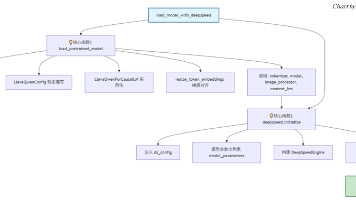
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型
正如知乎文章《自动驾驶 VLA 如何接入 BEV 等结构化输入》所指出的,VLA 落地自动驾驶的一大痛点在于:仅靠多视角原始图像,模型能“看见路”,却难真正掌握空间结构。因此,将 BEV、OD、OCC 等结构化感知接入大模型已成必然趋势。然而,这绝非简单的“多模态堆料”,而是在回答一个核心命题:怎样把车辆已构建的“空间世界模型”,精准翻译成大模型能理解和推理的 Token?
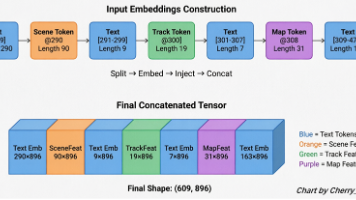
OpenDriveVLA 通过分层 Prompt 设计与基于占位符的跨模态注入机制,并非简单地将感知结果“翻译”给大模型,而是通过 Embedding 级的特征对齐与注入,让 LLM 直接“看见”并“理解”连续的物理世界。< (本文为CSDN原创,转载请注明出处。
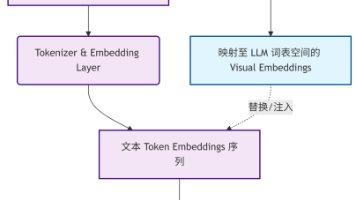
OpenDriveVLA 环境部署与推理实践》《OpenDriveVLA模型加载深度解析(推理阶段)》在 OpenDriveVLA 项目中,推理阶段的输入数据由接口返回。单帧数据中不仅包括多模态感知数据,还包括经标准化封装、可直接送入大语言模型的文本序列。很多开发者在复现或调试时,常对 question 与 prompt_question 的关系、ChatML 格式的必要性感到困惑。本文中,笔者结
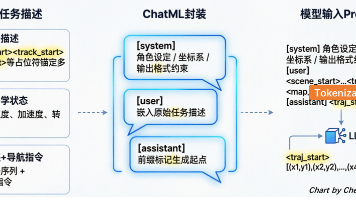
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型
OpenDriveVLA 是当前自动驾驶领域最受关注的视觉语言动作(Vision-Language-Action)模型之一,基于 Qwen2.5 系列大模型构建,能够直接从多模态输入(图像、文本指令)输出端到端的驾驶轨迹。本文将带你从零完成 OpenDriveVLA 的环境部署与推理验证,重点解决国内模型下载受限、分布式启动报错等问题。国内下载模型必须配置HF_ENDPOINT=https://h