




- @weixin_43549321
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这是索引的第3篇了,其实写到上一篇的时候,我就有些后悔。整个学习笔记是一边读一边写。有点像Milvus官网的翻译加注解的意思。但是,产品官网的重点,在于产品功能的罗列。但是,从学习的角度上来,这样的行文结构,就不太合理。向量数据库索引结构非常显著的分为索引、量化算法两大部分。而Milvus的索引实现,呈现出来是一个索引加一个量化的组合形态。前后有一些重复冗余的内容。如果索引归索引,量化归量化,拆分
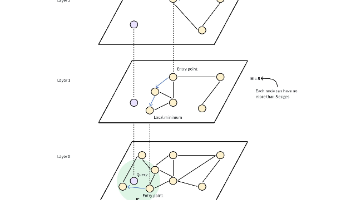
第一篇里面简要的提到了索引如何创建,并留下一个索引要新开一篇的坑。实际在学习的过程中来看,要理解Milvus全部的索引,开一篇都是不够的。所以这一篇只是叫索引篇1,后面肯定会有2.3…。要理解细节,还需要一步步来。
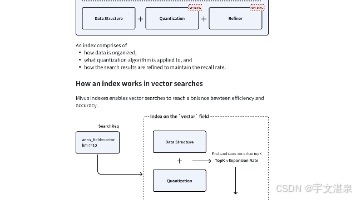
这是索引的第3篇了,其实写到上一篇的时候,我就有些后悔。整个学习笔记是一边读一边写。有点像Milvus官网的翻译加注解的意思。但是,产品官网的重点,在于产品功能的罗列。但是,从学习的角度上来,这样的行文结构,就不太合理。向量数据库索引结构非常显著的分为索引、量化算法两大部分。而Milvus的索引实现,呈现出来是一个索引加一个量化的组合形态。前后有一些重复冗余的内容。如果索引归索引,量化归量化,拆分
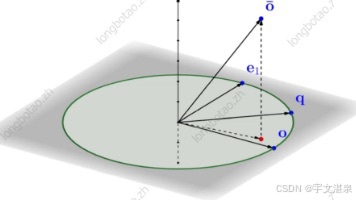
上一篇的IVF类索引,还差一个。那就是IVF_RABITQ索引。这个索引,是学习Milvus数据库以来,花时间最长的一个地方。因为要理解RABITQ索引的算法,稍微有些麻烦。在理解上和朋友们有一些交流,有些朋友直接劝说我用就可以了,不需要去理解它。确实,这个策略我是有一定程度的赞成的。就好像传统的数据库,我们天天用B-TREE的索引。但是对于使用这些索引的程序开发者,你正儿八经要他把B-TREE画
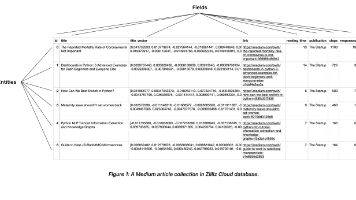
所以Schema定好了之后,插入的实体必须满足各个Schema的限定,才可以进入Collection。这类似关系数据,插入数据,每一列都要符合那一列的属性。一个Collection Schema有一个主键、最多四个向量字段、和几个标量字段。在官网创建Schema和添加字段的add_field示例代码来看,field应该是没有顺序概念的。所以猜测各个field的存储也是相互独立开的。这个从milvu
1.索引是额外的数据存储。索引是建立在数据之外的附加结构。索引优化的本质是用存储空间效率换查询过程的时间效率。2.索引是实现一些快速查询算法的存储基础。某些特殊的数据存放方法,也对应着查询时的一些算法使用。比如在B树的存储结构上,可以使用二分查找的算法。但是要注意,这个算法和后面Quantization的算法是两个不同的东西。