




- @weixin_43272162
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
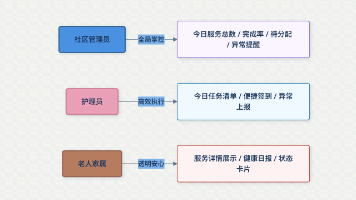
家里有老人接受社区照护的都知道,日常沟通基本靠三个群:家属群、护理员群、社区协调群。信息分散在不同人的聊天记录里,今天谁来、做了什么、下次什么时候——每个环节都可能掉链子。我接触到阳光社区的实际需求时,发现他们服务着 8 位老人,配了 5 名护理员,每天的照护任务接近 30 项。排班表一直在用 Excel,谁请假了临时调班全靠打电话,服务记录写在纸质本子上,家属想了解情况得单独找社区问。
Docker Compose是Docker官方开源的多容器编排工具,它允许用户使用YAML文件来定义由多个容器组成的应用服务。Compose文件描述了应用的容器、 networks、 volumes 和 configs 等资源。Docker Compose的工作流程非常清晰:首先,用户创建一个定义应用服务的文件;然后,使用命令启动所有服务;最后,通过命令停止并移除所有资源。Docker Compo
Linux性能调优是一个系统性的工程,需要综合考虑CPU、内存、磁盘I/O和网络等多个方面。性能监控基础:掌握top、vmstat、iostat等常用监控命令CPU调优:理解CPU指标、合理设置优先级和亲和性内存调优:分析内存使用、检测内存泄漏、优化配置磁盘I/O调优:选择合适的调度器、优化文件系统网络调优:调整内核参数、优化网卡配置实战案例:Web服务器、数据库、应用进程的具体优化先监控分析,再
WebSocket + 异步队列的组合方案,解决了实时 NLP 推理中连接开销和并发调度的核心矛盾。WebSocket 长连接消除重复的 TCP 握手开销,异步队列解耦消息接收和推理计算,Continuous Batching 提升 GPU 利用率。工程实现中需要注意连接生命周期管理、背压控制策略、模型热更新机制。核心原则是:通信层的优化解决延迟,计算层的优化解决吞吐,两者缺一不可。
本文通过一个看似"跨领域"的技术迁移案例——将工业级视觉缺陷检测中的CNN技术应用到零售推荐系统——系统性地阐述了AI能力跨领域复用的方法论和实践路径。技术本质的抽象:CNN的核心能力(局部感知、层级抽象、平移不变性、端到端学习)并不局限于图像处理,而是适用于任何具有局部依赖关系和层级结构的数据。理解算法的本质是技术迁移的前提。数据表示的转换:将用户行为序列重构为类似图像的"特征图"结构,是CNN
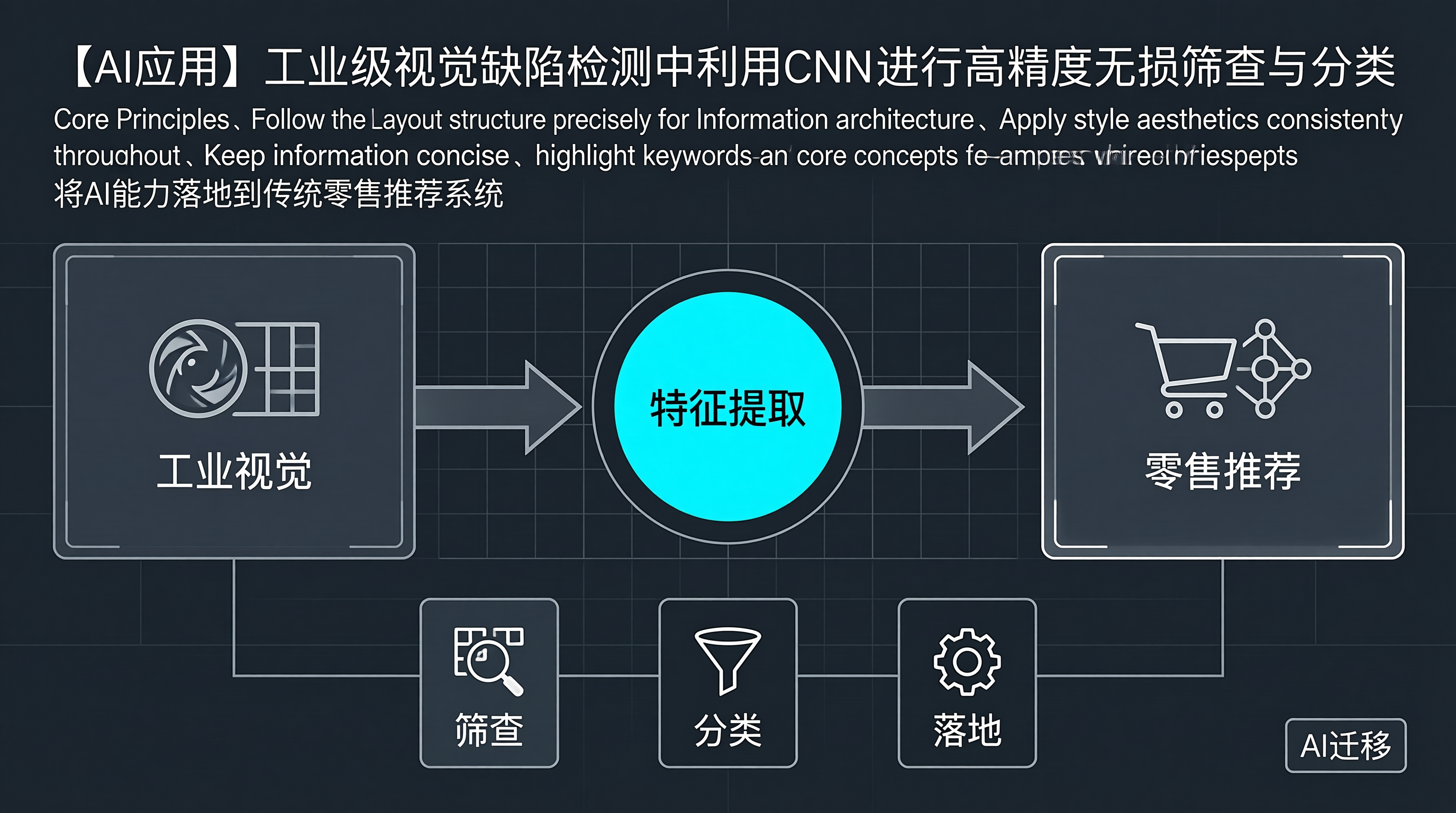
工业级视觉缺陷检测中CNN的应用,正在深刻改变传统制造业的质量控制模式。场景理解:工业缺陷检测面临缺陷尺度多样、背景复杂、实时性要求高等独特挑战。理解这些业务场景特点,是设计有效检测系统的前提。技术选型:分类网络适用于快速全检,检测网络适用于缺陷定位,分割网络适用于精确测量。根据具体业务需求选择合适的CNN架构和模型规模,是项目成功的关键。工程落地:数据采集与增强、光照系统设计、模型轻量化与加速、
模型量化是大模型推理部署的核心技术,目标是在精度可接受的前提下最大化压缩率。工程落地路径:第一步,使用动态量化快速验证基线精度,确认量化可行性;第二步,用校准数据集进行静态量化,获取更精确的缩放因子;第三步,对精度不达标的层进行敏感度分析,实施混合精度策略;第四步,对极致压缩需求使用 GPTQ 逐层最优量化。核心原则:量化不是越激进越好,而是要在目标部署硬件的约束下找到精度与效率的最优平衡点,用数

GPU 利用率低的首要排查步骤是区分数据供给瓶颈、通信瓶颈和计算瓶颈。nvidia-smi 的 GPU-Util 指标反映的是计算核心活跃度而非显存使用效率。PyTorch Profiler 提供算子级耗时分解,cudaMemcpyAsync 和 AllReduce 的占比是定位瓶颈的关键指标。优化的优先级应从数据供给开始(num_workers、数据预处理 cache、内存映射),再考虑通信优化
下面是多Agent通信协议的核心结构。代码注释解释了设计约束的原因。"""消息类型:不同类型决定接收方的处理行为"""REQUEST = "request" # 必须回复,有超时约束RESPONSE = "response" # 必须匹配request_idNOTIFICATION = "notify" # 不需要回复,但建议确认接收ERROR = "error" # 必须携带原因和可恢复性标记"
场景推荐方案不推荐方案高并发 I/O(HTTP、DB、文件)多线程CPU 密集型计算asyncio 协程I/O 与 CPU 混合asyncio + 进程池卸载纯协程低延迟要求(< 1ms)同步调用或 Go/RustPython 异步编程的核心价值在于以极低的资源开销实现高并发 I/O 处理。事件循环通过 epoll/kqueue 实现 I/O 多路复用,协程在 await 时主动让出控制权,使单线
