- @weixin_42828342
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
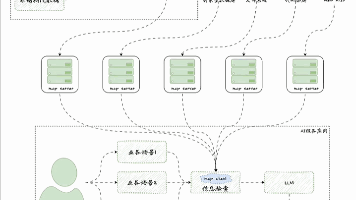
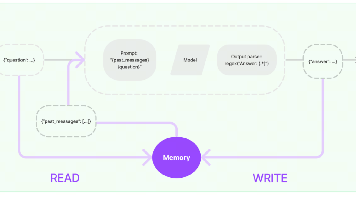
本文探讨了大语言模型的记忆存储问题及其解决方案。大语言模型本身是无状态的,无法记住上下文对话。为实现多轮对话记忆功能,需要额外模块存储历史信息。LangChain提供了Memory模块,通过ConversationChain或更现代的RunnableWithMessageHistory来实现对话历史管理。文章详细介绍了BaseChatMessageHistory抽象基类及其内存实现InMemory
LangChain的核心概念是链式调用(Chain),通过组合提示模板、模型和输出解析器等组件形成工作流。LCEL(LangChain表达式语言)提供了一种声明式语法来构建这种流程,具有模块化、可视化数据流和统一接口等特点。Runnable接口定义了链式调用的核心方法(invoke、batch等),所有组件都继承自该接口。基础用法展示了如何通过管道运算符(|)串联提示模板、模型和解析器,实现从用户
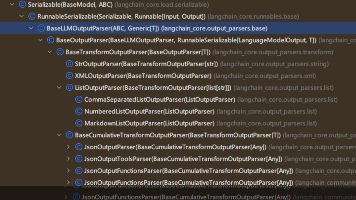
LangChain输出解析器介绍:输出解析器是将语言模型返回的字符串转换为结构化数据的关键组件,支持JSON、列表等多种格式。主要功能包括格式转换、数据校验和错误处理。常用解析器包括StrOutputParser(字符串)、JsonOutputParser(JSON)、ListOutputParser(列表)等。JsonOutputParser可通过提示词或get_format_instructi
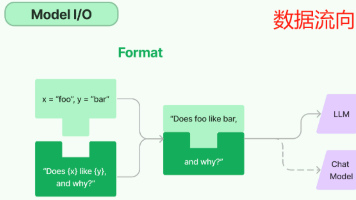
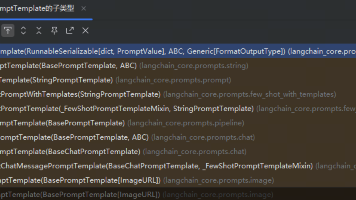
本文介绍了LangChain中的提示词模板(PromptTemplate)及其应用。提示词模板用于优化与大语言模型的交互,通过结构化方式包装用户输入,更清晰地表达意图。文章详细讲解了文本提示词模板的创建方法(构造方法、from_template等),以及部分提示词模板和组合提示词模板的实现技巧。同时介绍了format、invoke和partial三种格式化方法的使用场景,帮助开发者更好地构建和优化
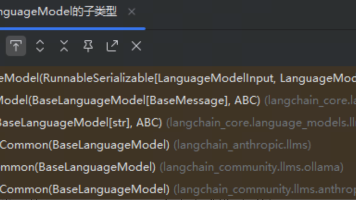
LangChain是一个支持集成多种大语言模型的工具框架,主要包括LLM(文本生成)、ChatModel(对话模型)和Embeddings(文本向量)三类模型。它通过标准化的接口和参数(如temperature、max_tokens等)统一调用方式,支持OpenAI、DeepSeek、Ollama等第三方模型。使用前需配置API密钥环境变量,通过python-dotenv加载密钥。LangChai
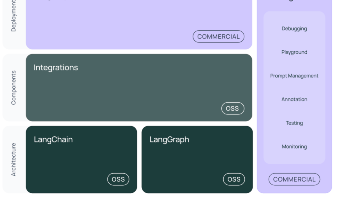
LangChain是一个基于Python的开源框架,旨在简化基于大型语言模型(LLM)的应用程序开发。它通过模块化设计将LLM与外部数据、工具和记忆组件连接起来,解决LLM的信息过时、无法执行操作和记忆有限三大痛点。 核心功能包括: 统一不同模型API的调用方式 提供现成的链式组装完成特定任务 支持文档加载、向量存储和外部工具集成 主要应用场景包括智能运维、日志分析、K8s故障诊断等。技术体系包含
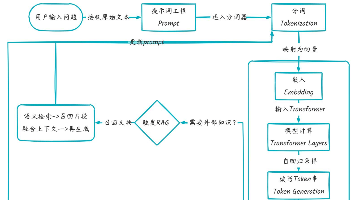
提示工程(Prompt Engineering),是指设计、编写、优化提示词(prompt)以最大限度发挥大语言模型(LLM)能力的技术和方法。一句话概括,提示工程就是“让 AI 更懂你”的一门技术。通过精心设计输入(prompt),你能引导模型生成你想要的答案、格式、风格或行为。

人工智能发展经历了从早期符号系统到当前大模型的演进过程。早期AI依赖人工规则(1950s-1980s),统计机器学习(1980s-2010s)实现了数据驱动学习,而深度学习(2012年起)通过神经网络自动提取特征。当前大模型时代(2020年起)以GPT、BERT等为代表,具有通用性强、多模态处理等特点,参数规模达千亿级。大模型通过预训练+微调方式,展现出零样本学习等能力,成为通向AGI(人工通用智
Ollama是一个开源的本地大模型运行与管理框架,支持离线运行DeepSeek、Qwen等主流开源模型,所有推理与数据处理均在本地完成,保障隐私与低延迟。文章介绍了通过Docker部署Ollama的方法,包括环境变量配置、模型下载建议(根据显存选择合适参数量的模型)以及常用管理命令。最后展示了使用LangChain调用本地模型进行文本生成的示例,验证了Ollama的本地推理能力。该工具特别适合对数

MCP(模型上下文协议)是Anthropic公司推出的大模型统一通信接口,旨在简化AI模型与外部工具和数据的集成过程。该协议通过标准化客户端(MCP Client)和服务器(MCP Server)之间的通信,解决了传统Function Calling需要编写大量中介代码的问题。