
写文章




- @weixin_42590734
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Deepseek-R1中 Grpo的策略模型的奖励函数
deepseek R1复现中的reward奖励机制函数
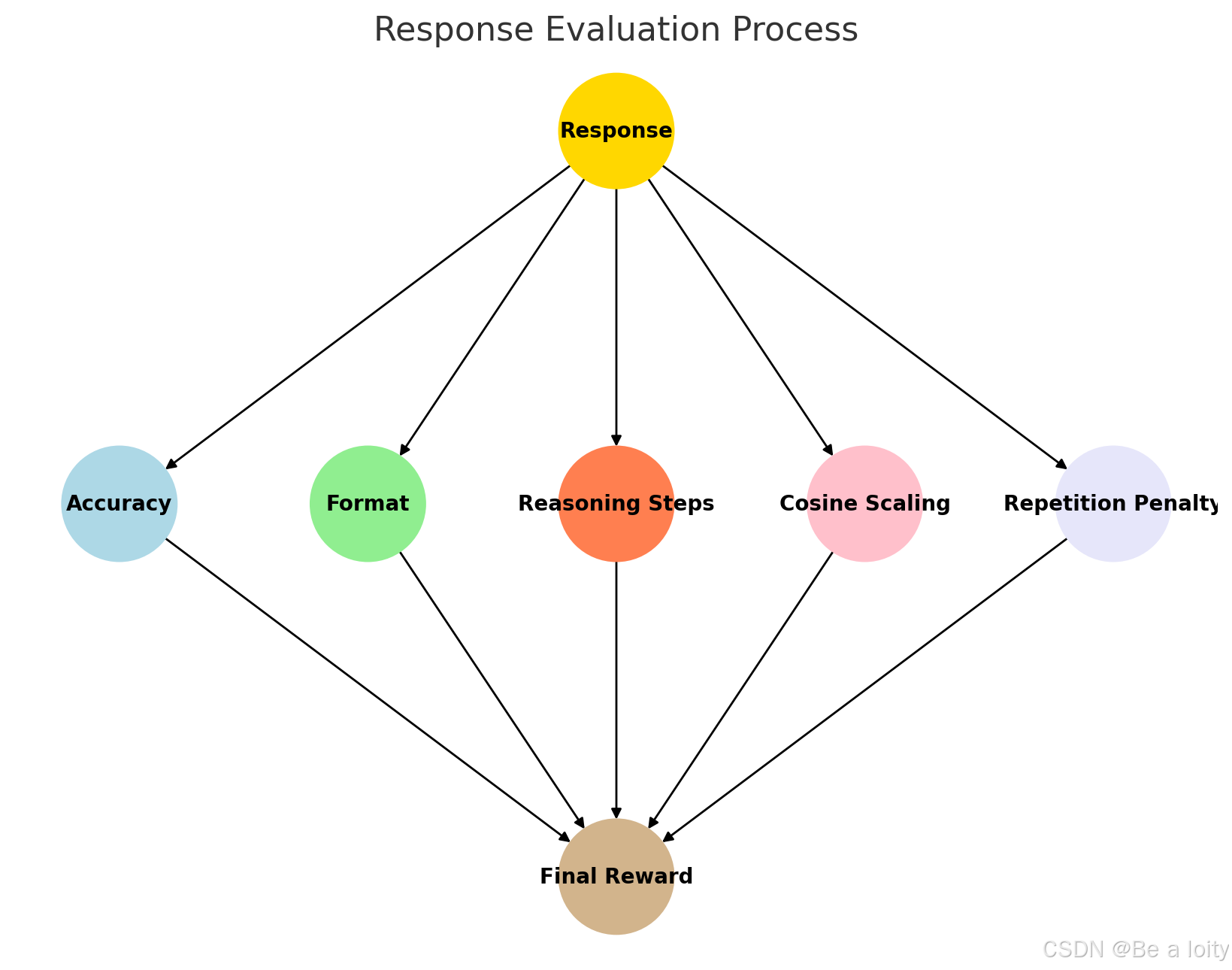
Deepseek-R1中 Grpo的策略模型的奖励函数
deepseek R1复现中的reward奖励机制函数
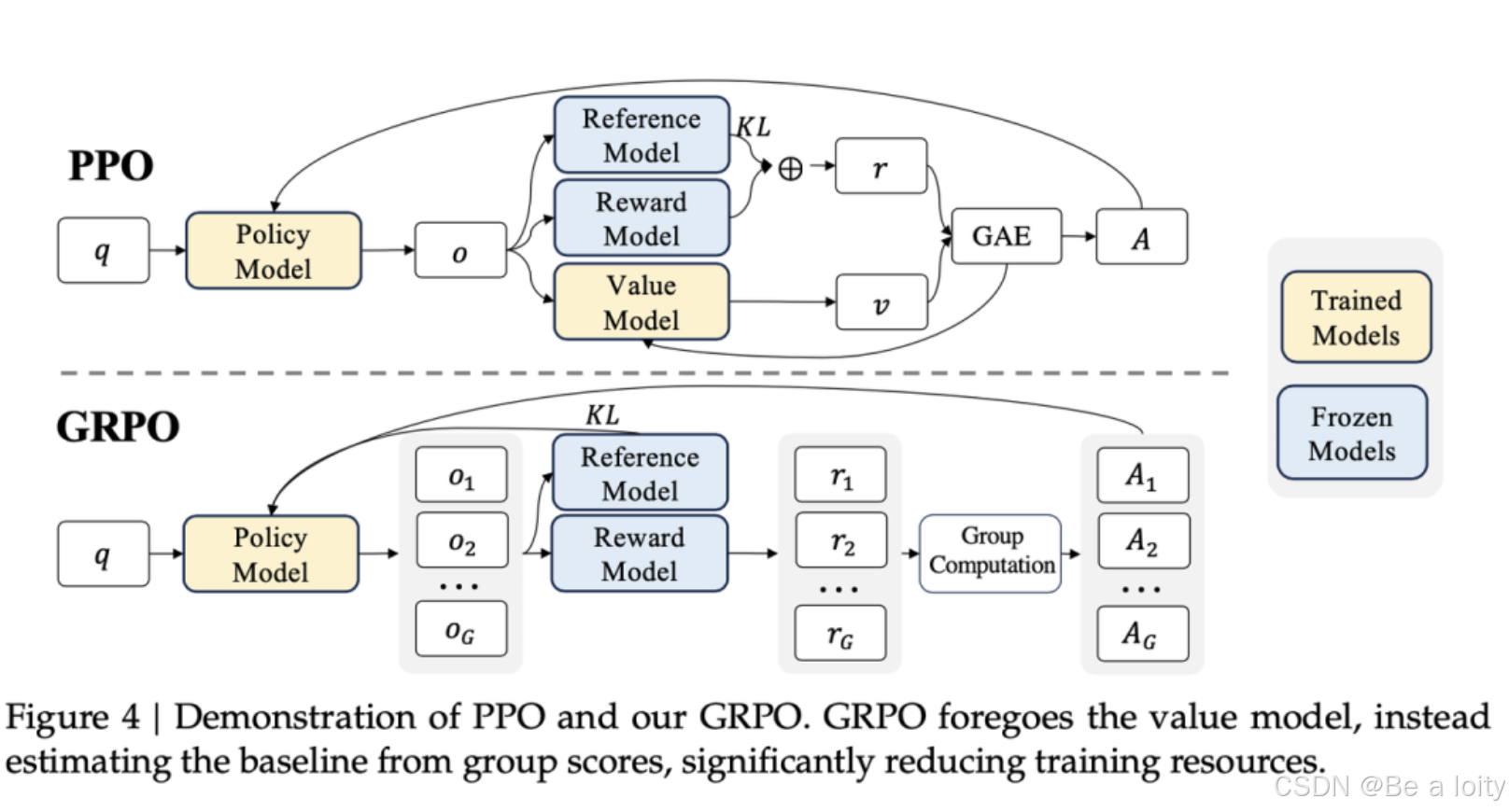
DeepSeek-R1 核心模块 GRPO学习
在LLMs的训练中,强化学习算法一直是提升模型性能的关键。然而,传统算法如PPO面临着计算开销大、策略更新不稳定等问题。今天,我们将深入解析DeepSeek-R1模型中的强化学习算法——GRPO(Group Relative Policy Optimization)。本文将为你详细解读GRPO的原理、实现细节以及在数学推理和代码生成任务中的卓越表现,带你一探究竟,了解这一算法如何革新大语言模型的训
到底了