




- @weixin_42058778
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文探讨企业部署大模型时的常见误区,重点分析显存占用和推理速度的计算方法。以Qwen3.5-35B-A3B-FP8模型为例,详细说明显存占用公式(模型权重+KV Cache),并演示不同上下文长度下的计算案例。在推理速度方面,通过算力和显存带宽的双重限制分析,推导出理论吞吐量约80 tokens/s,实际约60-70 tokens/s。最后介绍vLLM的优化价值,能显著提升GPU利用率和并发
摘要:本文探讨企业部署大模型时的常见误区,重点分析显存占用和推理速度的计算方法。以Qwen3.5-35B-A3B-FP8模型为例,详细说明显存占用公式(模型权重+KV Cache),并演示不同上下文长度下的计算案例。在推理速度方面,通过算力和显存带宽的双重限制分析,推导出理论吞吐量约80 tokens/s,实际约60-70 tokens/s。最后介绍vLLM的优化价值,能显著提升GPU利用率和并发
摘要:本文探讨企业部署大模型时的常见误区,重点分析显存占用和推理速度的计算方法。以Qwen3.5-35B-A3B-FP8模型为例,详细说明显存占用公式(模型权重+KV Cache),并演示不同上下文长度下的计算案例。在推理速度方面,通过算力和显存带宽的双重限制分析,推导出理论吞吐量约80 tokens/s,实际约60-70 tokens/s。最后介绍vLLM的优化价值,能显著提升GPU利用率和并发
“大龙虾” OpenClaw 引爆全球互联网,以其面向本地与私有化场景的架构设计、对工具调用与自动化执行的良好支持,在技术社区引发广泛关注,逐步成为开发者和技术团队构建“可长期运行的个人助理”的重要选择。本文将围绕 OpenClaw 的实际落地场景,系统分析其对模型底座与算力平台的核心要求,并结合本地部署实践,给出最适配的参考方案(截止到26年2月)。

Claude Code 对接本地大模型
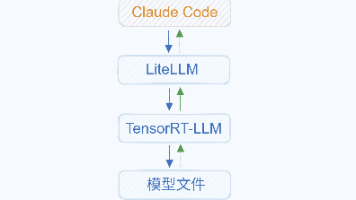
如果你反向代理之后,模型/智能体没有流式输出(打字机效果),请参考如下NGINX配置文件写法。OpenAI 等其他平台亦如此。
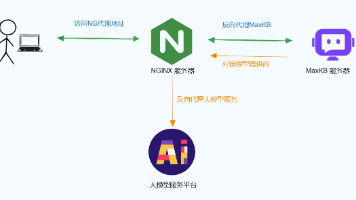
“大龙虾” OpenClaw 引爆全球互联网,以其面向本地与私有化场景的架构设计、对工具调用与自动化执行的良好支持,在技术社区引发广泛关注,逐步成为开发者和技术团队构建“可长期运行的个人助理”的重要选择。本文将围绕 OpenClaw 的实际落地场景,系统分析其对模型底座与算力平台的核心要求,并结合本地部署实践,给出最适配的参考方案(截止到26年2月)。
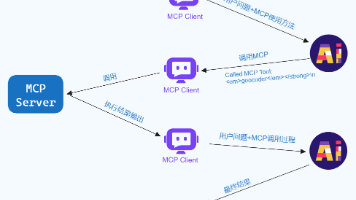
拆解 MCP 运行的底层原理
本文探讨了在RAG场景下使用公有大模型时的数据脱敏方案。提出两种工程化解决方案:方案一通过自定义函数预定义字典替换敏感词,具有速度快、准确度高、成本低的优势,但维护复杂;方案二利用私有小模型动态识别和替换敏感信息,灵活性更高但返回速度较慢且准确度中等。两种方案均采用工作流编排方式实现,能够有效防止企业敏感数据被大模型厂商利用,同时保持语义完整性。实际应用中可根据对速度、准确度和灵活性的需求选择合适
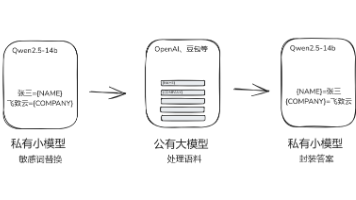
本文探讨了在RAG场景下使用公有大模型时的数据脱敏方案。提出两种工程化解决方案:方案一通过自定义函数预定义字典替换敏感词,具有速度快、准确度高、成本低的优势,但维护复杂;方案二利用私有小模型动态识别和替换敏感信息,灵活性更高但返回速度较慢且准确度中等。两种方案均采用工作流编排方式实现,能够有效防止企业敏感数据被大模型厂商利用,同时保持语义完整性。实际应用中可根据对速度、准确度和灵活性的需求选择合适