




- @weixin_37791303
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Java程序运行时,总是报java.lang.OutOfmemoryError: PermGen Space和java.lang.OutOfmemoryError: Java heap space内存溢出异常的报错。网上查要修改JVM的参数,加大java的运行内存,可以解决这个报错。但由于程序直接指向jar包运行,没有地方去修改java的参数。在使用java -jar启动的时候-Xms...
数据湖为多模态AI训练提供统一存储和管理方案,支持文本、图像、音频、视频等多种数据格式的整合。通过分层存储优化成本与性能,热存储用于高频访问数据,冷存储处理历史数据。数据湖具备多模态数据治理能力,包括元数据管理、数据清洗和标注工具集成,确保训练数据质量。此外,支持增量数据供给和版本控制,实现AI模型的持续训练优化。通过与TensorFlow/PyTorch等AI框架的无缝对接,以及分布式训练适配,
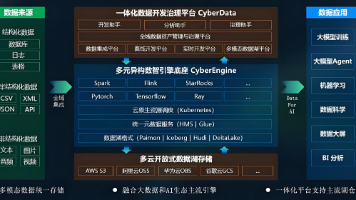
第四章、分布式消息队列第五章、大数据存储技术第六章、大规模数据离线计算分析第七章、实时计算框架第八章、时序数据分析框架第九章、机器学习框架第十章、数据聚合和关联技术第十一章、数据0异常点检测技术第十二章、故障诊断和分析策略第十三章、趋势预测算法第十四章、快速构建日志监控系统第十五章、微博广告智能监控系统第十六章、微博平台通用监控系统...
第一章、运维现状1.1 运维的职业和发展方向运维工程师( peration Engineer ),是指从事运维工作的工程师。运维工程师的工作范围非常广泛,包括服务器购买 租用和上架等基本管理,调整网络设备的配置管理和部署,服务器操作系统安装调试,测试环境和生产环境的初始化与维护,代码部署和管理( Git SVN 等),设计和部署线上服务的监控与报警,服务安全性检测(防止漏洞和攻击〉,数据库管理和调
数据湖为多模态AI训练提供统一存储和管理方案,支持文本、图像、音频、视频等多种数据格式的整合。通过分层存储优化成本与性能,热存储用于高频访问数据,冷存储处理历史数据。数据湖具备多模态数据治理能力,包括元数据管理、数据清洗和标注工具集成,确保训练数据质量。此外,支持增量数据供给和版本控制,实现AI模型的持续训练优化。通过与TensorFlow/PyTorch等AI框架的无缝对接,以及分布式训练适配,
数据湖主流建表引擎核心表类型必配参数适配场景HudiSparkMOR表/COW表主键(recordkey)、分区(partitionpath)实时CDC、近实时更新Iceberg基础分区表/隐藏分区表分区字段、Catalog配置PB级离线分析、动态分区管理Delta LakeSpark标准表/外部表事务日志(_delta_log)流批一体、数据合规审计PaimonFlink主键表/Append-O

数据结构(C语言版)严蔚敏第1章绪论1.1 简述下列术语:数据,数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。解:数据是对客观事物的符号表示。在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。数据对象是性质相同的数据元素的集合,是数据的一个子集。数据结构是相互之间存在一种或...
一、服务端配置:IP:192.168.1.10(1)备份 /ect/ntp.conf ,删除该文件,新建空文件vim /etc/ntp.confdriftfile /var/lib/ntp/driftrestrict default nomodify notrap #允许所有IP客户机restrict 127.0.0.1 #允许本地同步,便于监控,配置restrict -6 :::1...
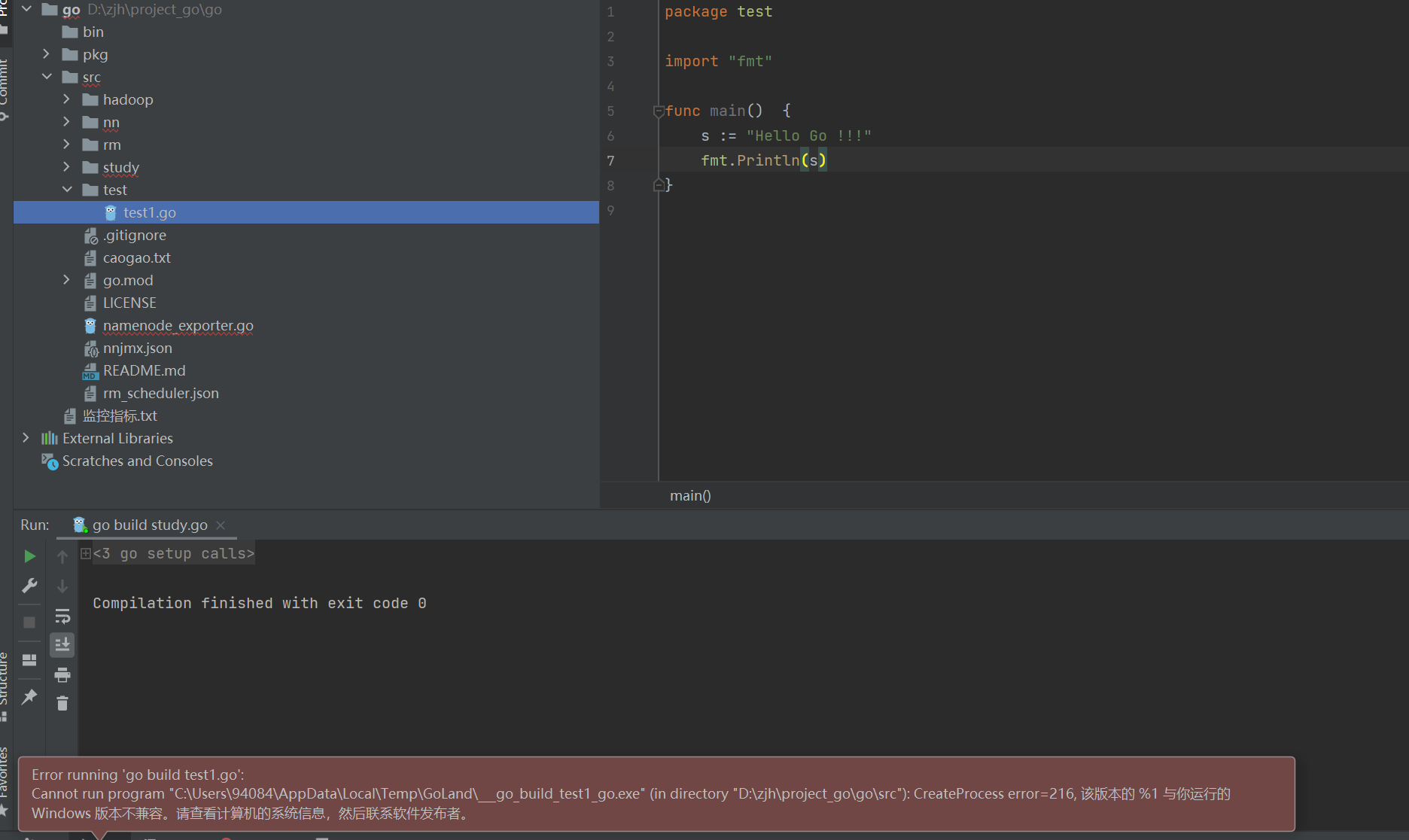
Error running ‘go build hello.go’: Cannot run program “C:\Users\Administrator\AppData\Local\Temp___go_build_hello_go.exe” (in directory “G:\go\workspace”): CreateProcess error=216, 该版本的 %1 与你运行的 Windo
在这里插入代码片`[root@ ~]# yum install ipmi*Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-managerThis system is not registered with an entitlement server. You can use subscrip...