




- @weiwei935707936
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(文章写得非常好,看不懂的是傻瓜......)GCN问世已经有几年了(2016年就诞生了),但是这两年尤为火爆。本人愚钝,一直没能搞懂这个GCN为何物,最开始是看清华写的一篇三四十页的综述,读了几页就没读了;后来直接拜读GCN的开山之作,也是读到中间的数学部分就跪了;再后来在知乎上看大神们的讲解,直接被排山倒海般的公式——什么傅里叶变换、什么拉普拉斯算子等等,给搞蒙了,越读越觉得:“哇这些大佬好厉
一.RCNN(Region-CNN)目标检测的奠基算法步骤:Step1:提取候选区域Step2:用CNN提取特征Step3:用SVM分类Step4:检测框回归提出原因:作者说HOG和SIFI提取特征已经过时了,CNN用来提取特征非常好存在的疑问:结果有点歪...
一篇国外大佬发文:国外大佬发文:让AI自己给数据加标签,然后把损失函数用相应的方式来表达:把自动加标签的噪音和可能的偏差都考虑进去。最近有两篇研究,都是这方面的例子:一是MixMatch: A Holistic Approach to Semi-Supervised LearningArxiv码:1905.02249二是Unsupervised Data Augmentatio...
一.GAN的基本要素1.真实数据集,初始化虚假数据集(噪音)2.生成器,鉴别器:生成器:输入:原始数据的维数(一条数据)输出:原始数据的维数(一条数据)...
多模态推荐系统(WWW'2023), 多模态推荐数据集
BCELoss:CE和BCE:CrossEntropy。 B:binary,即用于二分类问题输入:Sigmoid:目标:损失函数:BCEWithLogitsLoss:就是把Sigmoid-BCELoss合成一步BPRLoss:推荐系统领域有两个问题:Raking和RatingRanking:Top-N的推荐Rating:预测物品打分最新研究都是做排序的:排序比较贴近实际
一.直接理解作用:解决面对类别不同,模型泛化能力不强的问题方法:meta training阶段:将数据集分成不同的meta task(即:假设有n个类别,每次取出其中的C个类别进行训练,每个类别K个样本——C-way K-shot problem)meta test阶段:面对全新的类别,不需要变动已有的模型就可完成训练。...
一.transformer编码器transformer模型的直觉:positional encoding(位置嵌入|编码)self attention mechanism(自注意力机制与注意力矩阵可视化)layer normalization和残差连接transformer encoder整体结构二.transformer代码解读参考视频:https://www.bi...
多模态推荐系统(WWW'2023), 多模态推荐数据集
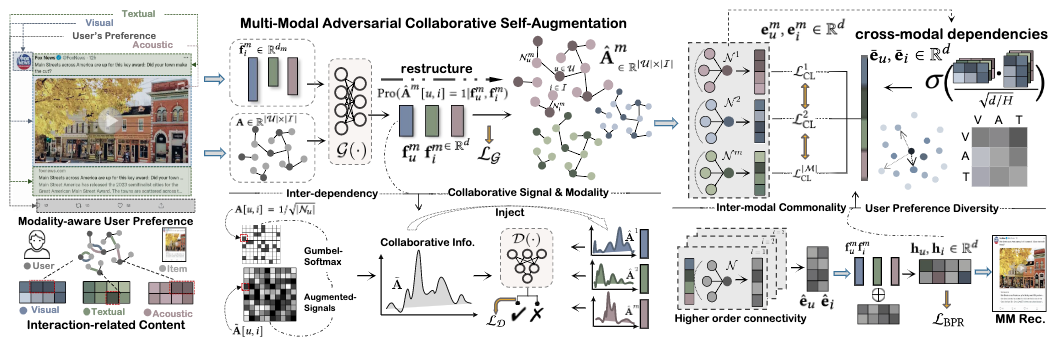
摘要: (这篇文章就觉得, 它是通过动态图解决了隐式反馈一些偶然的交互边的问题)将用户的隐式反馈重组为用户-商品交互图有助于图卷积网络(GCNs)在推荐任务中的应用。在交互图中,用户节点与商品节点之间的边作为gcns的主要元素,进行信息传播,生成信息表示。然而,一个潜在的挑战在于交互图的质量,因为观察到的交互与不太感兴趣的项目发生在隐式反馈中(比如,用户偶然浏览了微视频)。这意味着带有这种假阳性边