




- @star1210644725
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近的一部分工作,有在做RAG的benchmark。年初三四月份(2024)的时候,调研已有的测试方案的时候,相关工作很少,只有一篇论文。最近再看相关的测试数据集又多了一些。我们虽然也有构建数据集,但是还是相对少一些。今天分享一篇论文,RAG关于法律领域的测试数据集。通常这种数据集需要一些领域知识,才能更好的更充分的构建出来这个数据集。实际上,评估RAG的能力,使用通用数据集是远远不够的。专门的领

最近在做RAG的雕花工作。想要在PDF解析上,能够有一定的突破。上上周调研了一周的PDF解析的组件。但是还是没有一个开源的解析的很不错的组件。这篇文章,一起来看看是否能从PDF文件的底层数据结构上入手,来进行解析。PDF(Portable Document Format,可移植文档格式)是一种广泛使用的文件格式,用于呈现文档,包括文本、图像和多媒体内容。PDF文件的存储原理和结构设计得非常复杂,以

《Cursor使用体验与优化建议》摘要: Cursor能显著提升编码效率,但存在代码冗余、思路不匹配等问题。主要痛点包括:1)直接生成代码而非先确认思路;2)产生大量冗余类/函数;3)生成陌生代码引发焦虑。优化建议:明确任务边界(函数级到类级)、人工校验输出、结合版本控制。实用技巧:拆分高内聚类、避免传递运行日志、精准描述需求(写什么/怎么写/写哪里)。注意:适合工程任务而非算法,且需人工检查LL
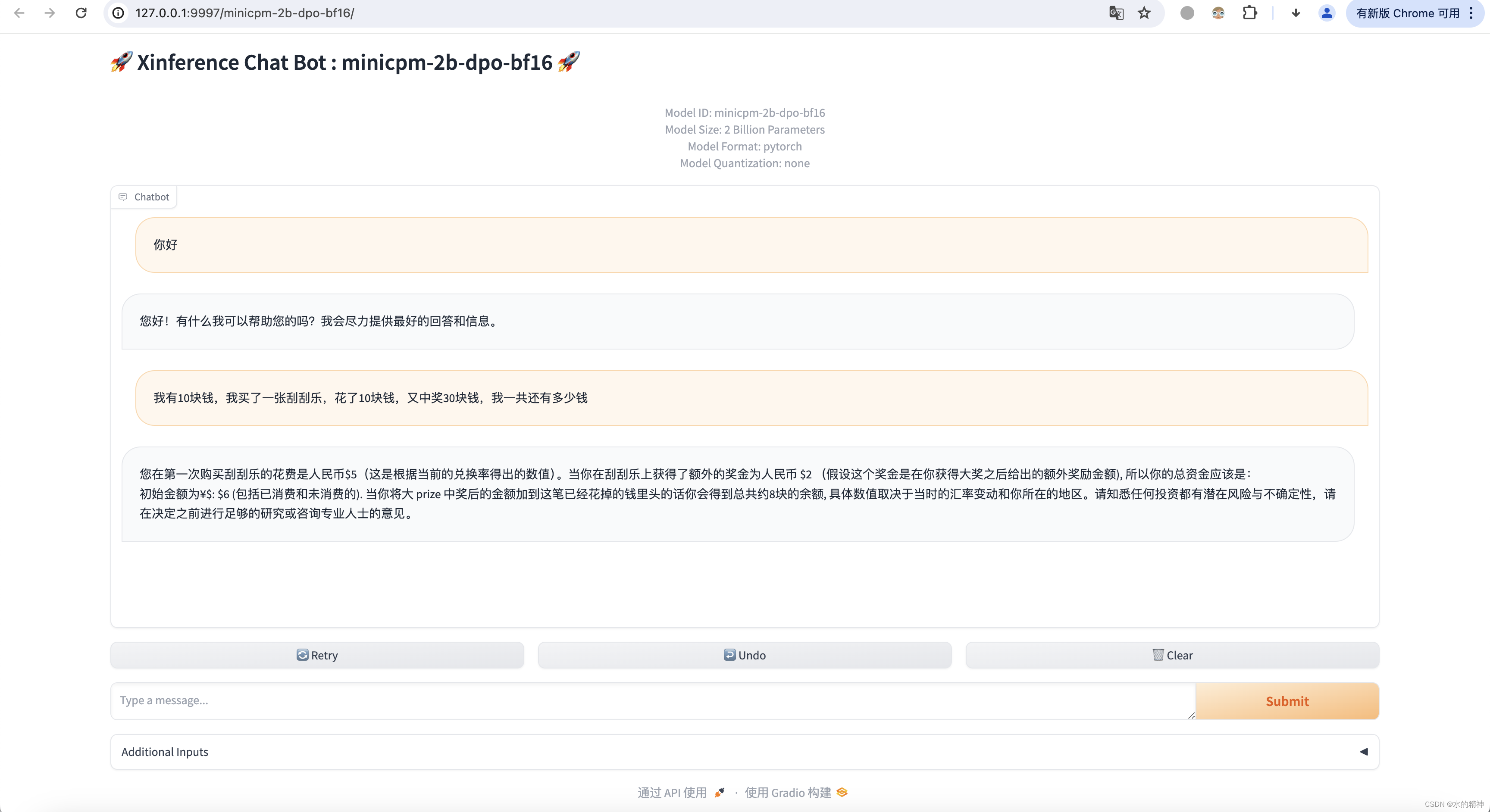
我的环境是mac m2 32G ,没办法用GPU。这是X inference的安装教程。这里是mac部署2B的教程。还有测试推理的效果,速度
不同检索方式说明最近在做搜索召回提升相关的研究工作。对比了稀疏检索和稠密向量检索的效果。其中使用的搜索引擎为elasticsearch8.x版本。稀疏检索包括BM25的检索方式,以及es官方在8.8之后版本提供的稀疏向量模型的方式。稠密向量检索,是指借助机器学习的模型做文本嵌入,然后用es8.x以后版本提供的向量检索。测试数据说明测试数据包括了中文和英文,涉及了法律和新闻数据。

应用同事反馈,在使用es的滚动导出的时候,一共有5567条数据,但是实际上只拿到4567条数据,并且打断点,最后一次是获取到了456条数据。所以可以判断,中间少了1000条数据。因为滚动导出是每次1000条。初步判断,是少了一次数据解析,有可能第一次构建请求的时候,没有解析数据。实际上并不是,看报错如下图,是 entity content is too long[xxx1] for the con

关于clickHouse数据库,它也是一种关系型数据库。但是区别于传统关系型数据库mysql以及Oracle。其中最大的区别就是传统的关系型数据库是行式存储,而clickHouse是列式存储。请记住这个列式存储方式。这种结构存储方式,具备了一种天然的优势,就是做统计分析,聚类分析。本身数据库没有绝对的优劣之分。关于clickHouse和mysql的对比,但空间唯独上可以抽象为行(横轴)列(纵轴)。
一份个人简历,大四提前一年出来实习,在12306。2020年毕业,开始第二份正式工作。从大学毕业,只是我学习之路的刚刚开始。简历所写的内容都是真实的,一点水分没有。欢迎拍砖,希望大家能够针对我的简历,提出一些意见。深耕Elasticsearch,网关,JVM虚拟机,spring源码,多线程以及线程安全。最感兴趣的是k8s,以及服务网格。这会是未来的学习方向。心怀一颗去大厂的梦,因为哪里有一群愿景,
将json数据导入到ES集群——解决方案对比&填坑日记
全部城市的中心点坐标,json格式。后台可以直接使用。{"city": {"上海": [121.487899486, 31.24916171],"临沧": [100.092612914, 23.8878061038],"丽江": [100.229628399, 26.8753510895],"保山": [99.1779956133, 25.1204891962],"大理白族自治州": [100.2