- @specssss
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这款机器人的动作灵活,可以执行复杂的任务,如从地面自行站立等特别是在复杂和狭窄的空间中,提高了机器人在实际工作环境中的适用性。4、先进的软件和AI工具:配备了最新的AI和机器学习工具,如强化学习和计算机视觉,确保机器人能够适应并高效处理复杂的实际情况。2、增强的力量和灵活性:电动Atlas具有比以往任何一代更强大的力量和更广泛的运动范围,使其能够执行更复杂的操作和任务。3、实用的工业应用设计:设计

在这个日新月异的数字时代,每一次技术的飞跃都是对极限的挑战与超越。而作为当下性能最为出色的芯片,RTX4090无疑是许多人对于算力、GPU性能追求的首选,其惊人的CUDA核心数量,配合高速GDDR6X显存,无论是深度学习、高帧率4K/8K专业图形渲染,还是进行AI大模型推理,都能轻松驾驭,游刃有余。高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.ht
包括OpenAI、Anthropic、Mistral、LLama2、Anyscale、Google Gemini等。GitHub:https://github.com/Portkey-AI/gateway官网:https://portkey.ai/features/ai-gateway。Portkey AI Gateway就像是一个AI模型的交换站,让开发者可以方便地使用和切换多种AI服务。安装体
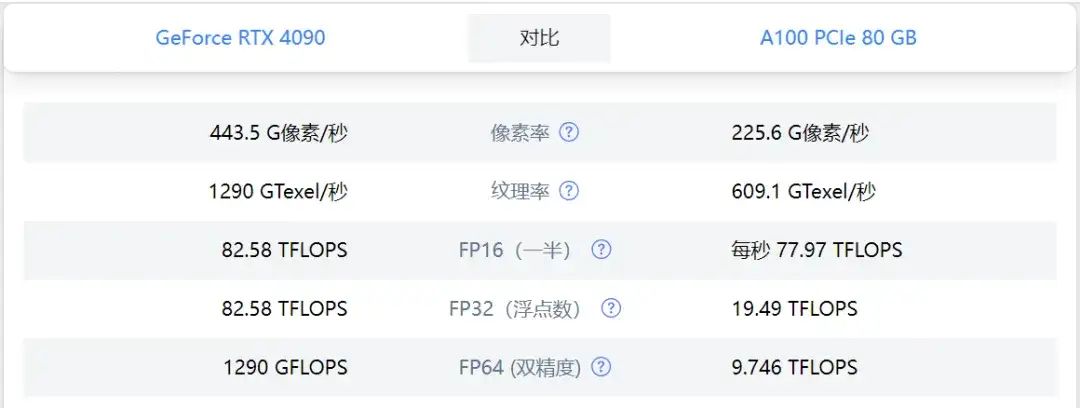
在进行深度学习和人工智能的应用时,挑选最合适的硬件工具对于模型的训练和推断任务显得尤为关键。尤其在大模型的训练上,英伟达4090或许并不是最合适的选项。进行训练任务时,通常要求有更大的显示存储容量、更宽的内存带宽以及更出色的计算性能。此外,还必须能够适应海量数据处理需求,如实时视频图像分析等。考虑到这些需求,英伟达的高性能显卡系列,比如A100和H100,通常更适合处理大量的数据集和复杂的模型。但

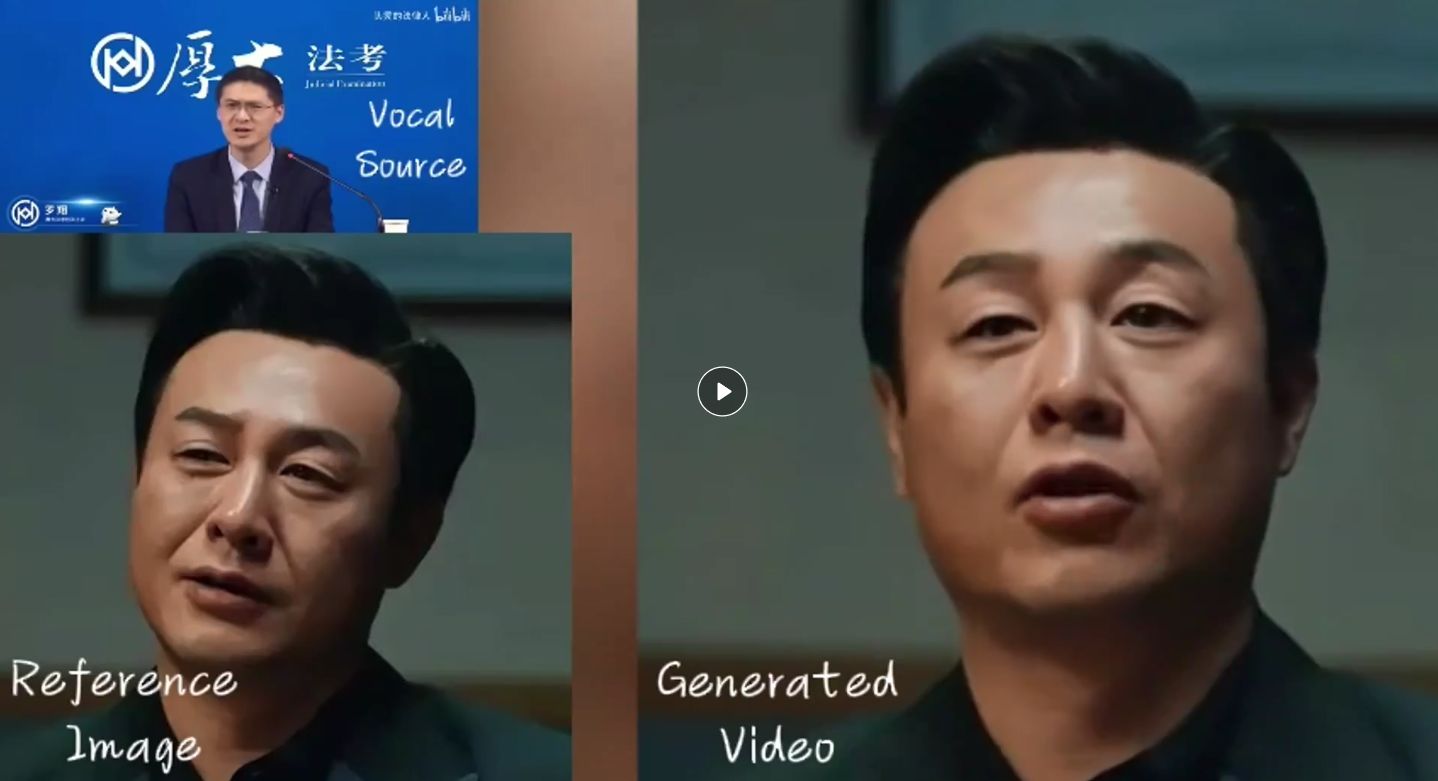
EMO特别强调在视频中生成自然而富有表情的面部动作,能够捕捉到音频中情感的细微差别,并将其反映在人像的表情上,从而生成看起来自然、生动的面部动画。该技术不限于特定语言或音乐风格,能够处理多种语言的音频输入,并且支持多样化的肖像风格,包括历史人物、绘画作品、3D模型和AI生成内容等。EMO能够实现不同演员之间的表现转换,使得一位演员的虚拟形象能够模仿另一位演员或声音的特定表演,拓展了角色描绘的多样性
Lumina 分析了一个庞大的学术资源数据库,以结合上下文和简单的方式回答您的问题。收集了超过 200,000 篇索引期刊文章。它能够帮助用户,理解复杂概念、查找期刊文章甚至执行编写实验程序等任务的一体化工具。可以说是科研用户群体的福利。使用 Lumina,您只需点击几下即可轻松找到准确的答案并探索相关资源。Lumina 突出显示每个来源的特定部分,确保透明度和可信度。告别整理研究的繁琐过程,迎接
这是一个最先进的AI,可以绘制任何二次元风格的绘画!无论您是在寻找可爱的Q版角色还是充满动感的动作场景,niji・journey 都能将您的想象变为现实。计划在2月底的全面发布中引入一系列新功能,如vary(Region 调整图片的某个部分)、pan(移动)和zoom(缩放),进一步增强用户体验和创作灵活性。Niji V6致力于理解并将各种主题转化为动漫风格的视觉作品,即使是一些平时动漫里不常见的

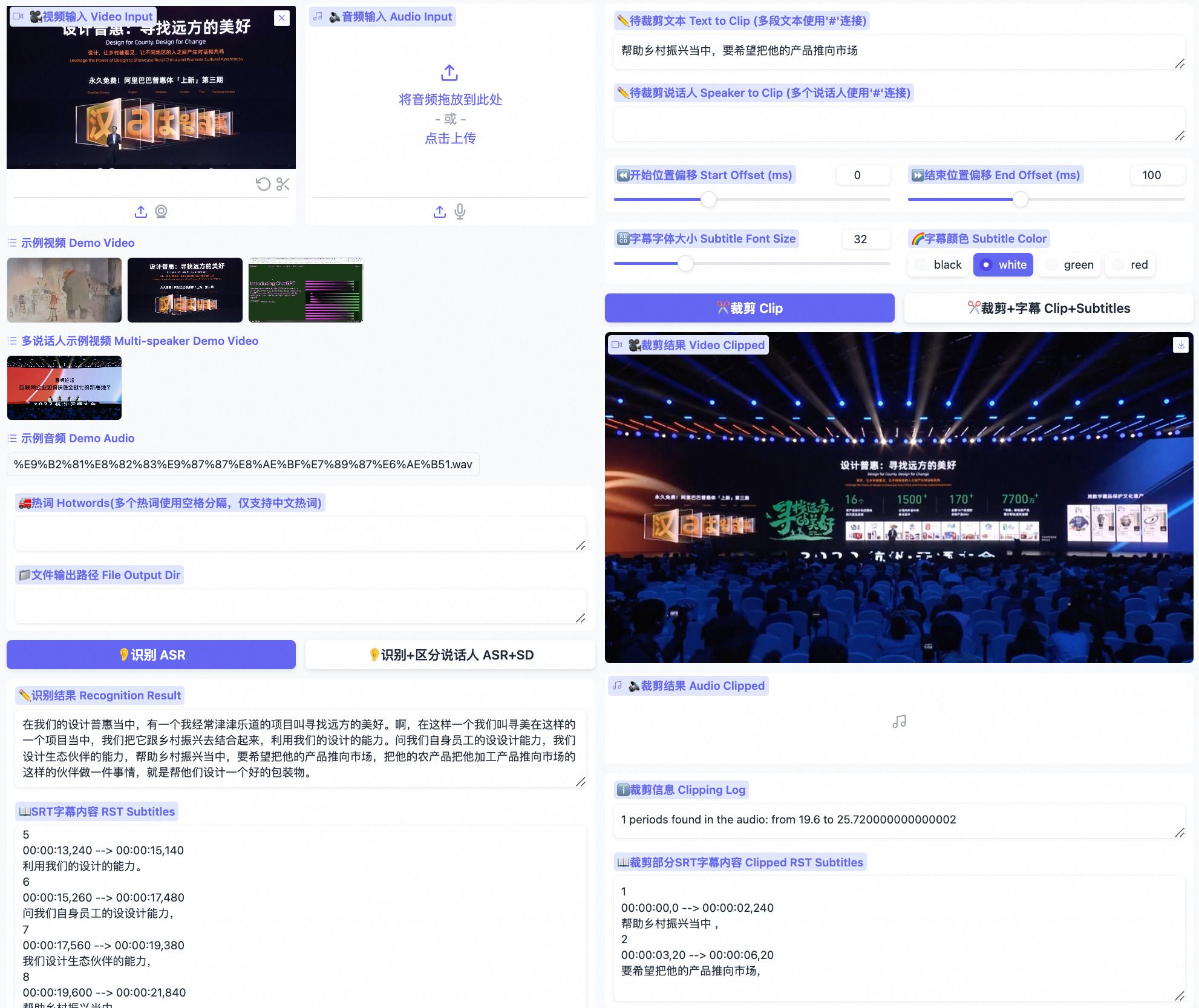
高性价比GPU资源:https://www.ucloud.cn/site/active/gpu.html?你可以根据识别结果选择文本片段或说话人进行视频裁剪。Funclip不仅支持中文,未来还将支持英文视频剪辑,是视频内容创作者和编辑者的理想选择。它能够自动识别视频中的中文语音并允许用户根据语音内容来裁剪视频。该工具使用了阿里巴巴语音识别模型FunASR Paraformer-Large确保了剪辑
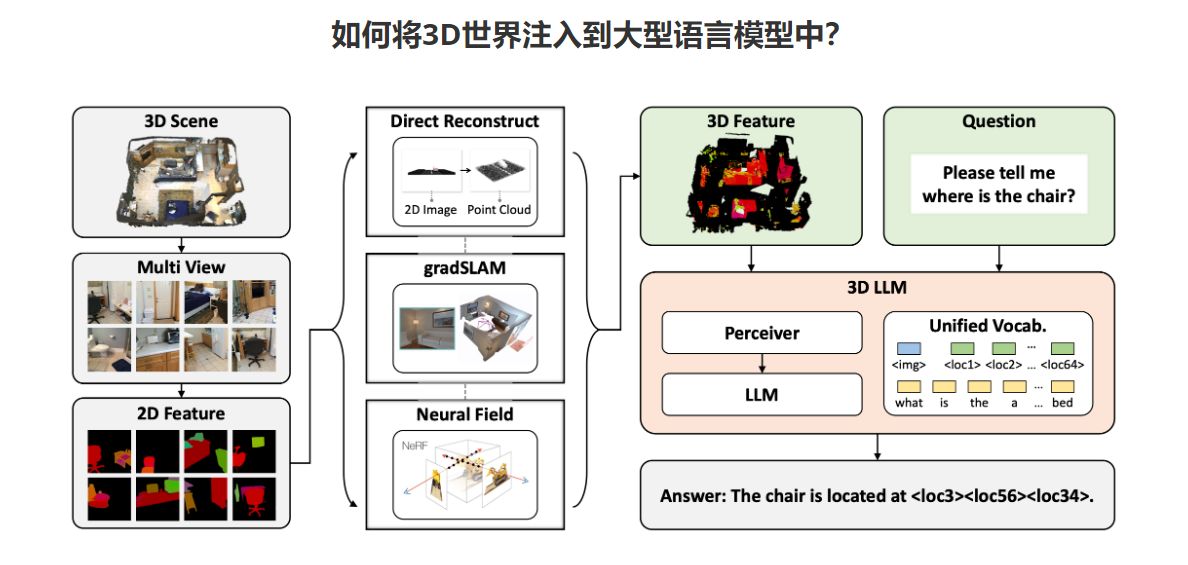
为了有效地训练 3D-LLM,我们首先利用 3D 特征提取器从渲染的多视图图像中获取 3D 特征。尽管这些模型非常强大,但它们并不以 3D 物理世界为基础,而 3D 物理世界涉及更丰富的概念,例如空间关系、可供性、物理、布局等。此外,对我们保留的 3D 字幕、任务组合和 3D 辅助对话数据集进行的实验表明,我们的模型优于 2D VLM。具体来说,3D-LLM 可以将 3D 点云及其特征作为输入,并
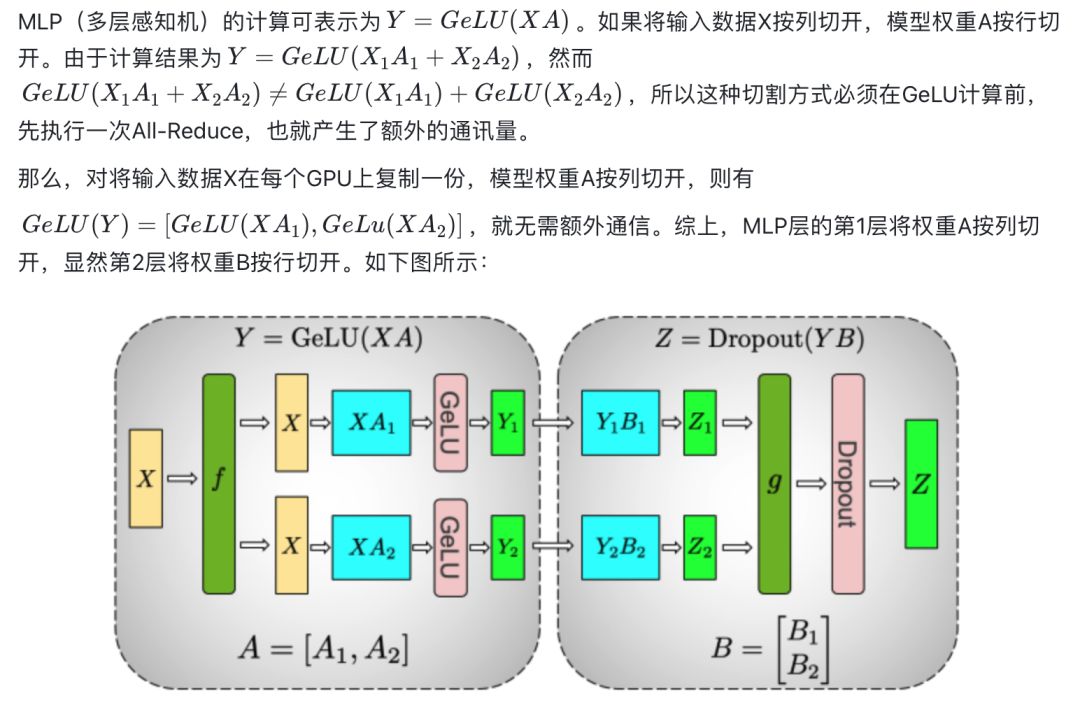
右图是MP+DP模式,64个GPU(可理解为64台机器,1台机器1个GPU,此时相当于DP模式)的计算效率有96%之高,是由于DP在计算梯度时,可一边继续往下做Backward,一边把梯度发送出去和DP组内其他GPU做All-Reduce。同理,当GPU个数增多,GPU的计算效率也会下降。All-Reduce操作包括Reduce-Scatter操作和All-Gather操作,每个操作的通讯量都相等