
写文章




- @saltfish920
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
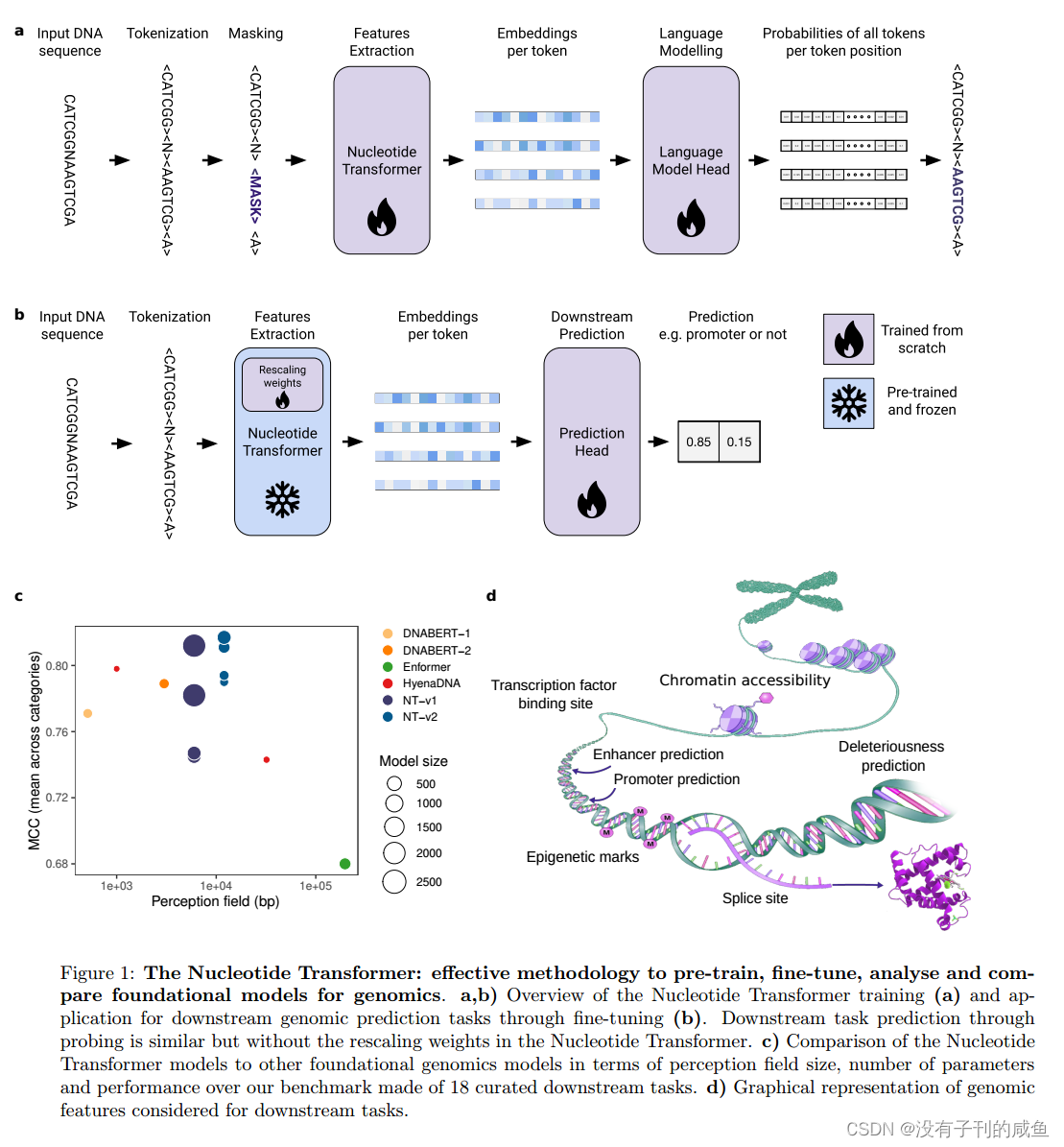
论文阅读笔记(二)——The Nucleotide Transformer
缩小可测量遗传信息和可观察性状之间的差距是基因组学长期面临的挑战。然而,仅从DNA序列预测分子表型仍然是有限和不准确的,通常是由于缺乏注释数据和无法在预测任务之间转移学习。在此,我们对DNA序列预先训练的基础模型进行了广泛的研究,命名为Nucleotide Transformer,其参数范围从50M到2.5B不等,并整合了来自3,202种不同人类基因组的信息,以及来自不同门(包括模式生物和非模式生
到底了