
写文章




- @qq_57597568
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
微调BERT模型实现文本分类
模型微调只是针对某种下游任务,针对性的强化模型的能力,但是微调之后的模型在泛化能力上有所下降。

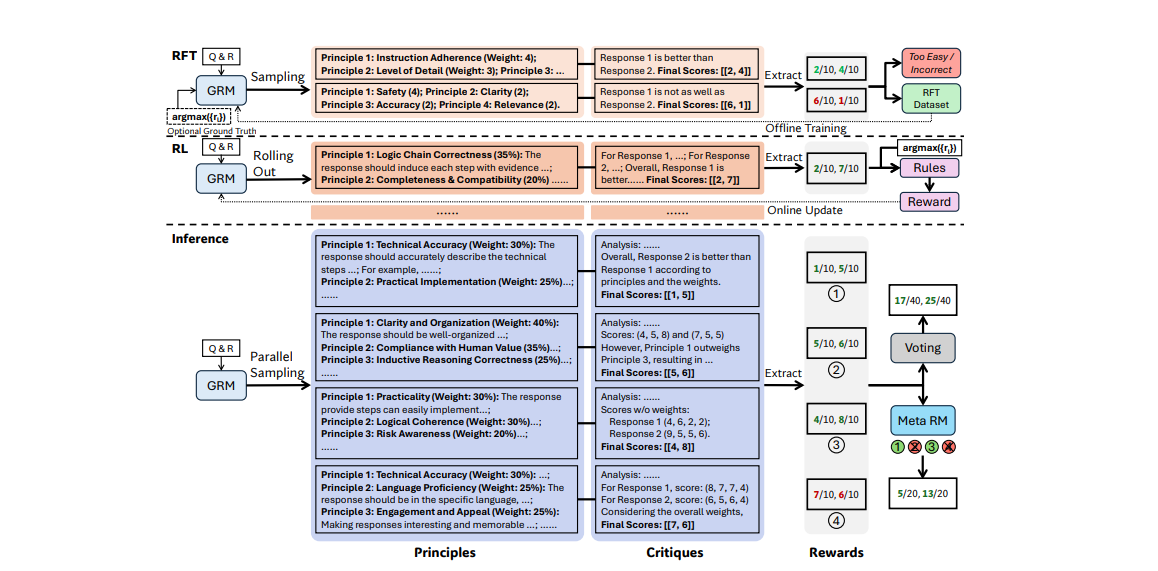
Inference-Time Scaling for Generalist Reward Modeling
清华联手deepseek推出新的通用强化学习奖励标准
微调BERT模型实现文本分类
模型微调只是针对某种下游任务,针对性的强化模型的能力,但是微调之后的模型在泛化能力上有所下降。
DeepSeek系列论文解读四之DeepSeek Prover V2
创新点贡献描述冷启动推理数据生成方法形式化优先,反向配对非正式语言,构建更严谨的训练样本子目标驱动的递归证明流程支持复杂定理分层解构,大幅提升模型效率与可扩展性非 CoT + CoT 模型协同训练策略兼顾速度与解释性,适应多场景使用结构奖励强化学习框架(GRPO)强化“多步逻辑链”保留,提升复杂任务稳定性ProverBench 数据集首次引入教材与竞赛混合评测集,扩大了评估覆盖范围。

到底了