- @qq_46111980
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SyncCaster 是一款用于多平台内容分发的 Chrome 浏览器扩展,支持从自撰写/网页采集文章并统一转换为 Markdown,通过 DOM 自动化方式将内容一键同步发布到掘金、CSDN、知乎、微信公众号等多个主流平台,适合需要高效进行多平台内容发布的技术博主和内容创作者。🔒 扩展完全本地运行,不收集、不存储任何用户信息。

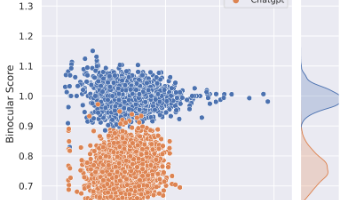
论文在解决什么问题?大模型写的文本越来越像人,传统基于训练的检测器往往只对特定模型(比如 ChatGPT)有效,一旦换成别的 LLM 或新版本,性能就会大幅下降。论文提出Binoculars——一种只用两只预训练语言模型、完全不需要训练数据的零样本 LLM 文本检测方法,目标是在不知道“谁写的”的前提下区分「人类写作」和「机器生成」。有什么历史意义 / 性能突破?在完全零样本的前提下,Binocu
MCP(模型上下文协议)为AI与外部世界之间搭建了一座桥梁。它通过标准化接口让不同AI和工具能够互通互联,极大地降低了开发与集成的复杂度。
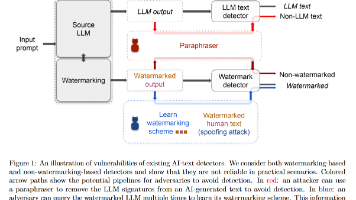
在现实世界里,AI 生成文本究竟能不能被“可靠地”检测出来?不是在干净的 benchmark 上,不是在“老实人”场景里,而是在有攻击者、有动机、有时间专门绕过检测器的情况下。作者做了两件事:一方面,他们系统性地“压力测试”了当下主流的 AI 文本检测方案,包括水印、训练好的分类器、DetectGPT 这类 zero-shot 检测器以及基于检索的检测器;就算你有“最强可能的检测器”,当 AI 文
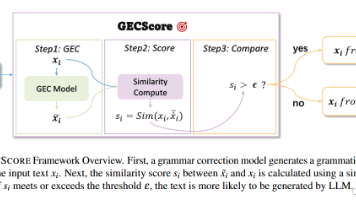
这篇论文解决了什么问题?在大模型时代,我们越来越需要区分“人写的”还是“模型写的”文本。传统零样本检测方法大多需要访问“源模型的 logits”(白盒),或者依赖大量训练数据(监督式分类器)。这篇论文提出的GECSCORE在完全黑盒、零样本的条件下,仅凭一个语法纠错模型,就能高精度识别 LLM 生成文本。有什么历史意义和性能突破?
我们已经习惯了“整篇文章是不是 AI 写的”这种粗粒度检测,但现实里,人们更常做的是用大模型润色、补写某几段,而不是整篇托管给 AI。现有的 DetectGPT、GPTZero 之类方法,都更擅长识别整篇机器写作,对“一句一句地查”几乎无能为力。SeqXGPT 正好把刀磨到了这个细粒度问题上。如何在句子级别判断一段文本究竟是人写的,还是被某个 LLM 生成或改写过的。

论文在回答一个让人很焦虑的问题:在大模型生成文本已经“像人一样”的今天,我们还能不能可靠地区分“人写的”和“模型写的”?在绝大多数现实场景里,只要你肯收集足够多的样本,检测不是不可能,而是“迟早可以”。它纠正了最近一波“检测不可能论”的悲观结论。之前有工作证明,当人类文本分布和模型文本分布非常接近时,基于单条文本的检测器理论上很难做得比随机好太多,于是许多讨论直接滑向“LLM 文本检测从根上不可能
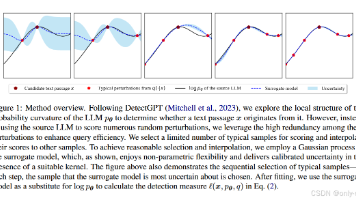
如何在几乎不多问大模型的情况下,依然靠谱地分辨一段文字是不是 LLM 写的?过去的零样本检测方法,要么像传统的 log-prob 检测器那样效果一般,要么像 DetectGPT 那样效果不错但查询次数离谱——检测一段文本要几百次调用源模型。在商用 LLM 按 token 收费的大背景下,这个成本几乎不可接受。在 DetectGPT 的框架里塞进了一个“贝叶斯代理人”
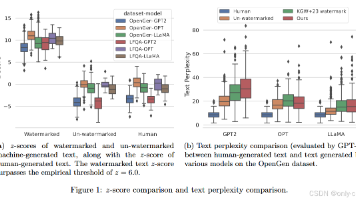
我们能否“可靠地标记出”哪段文本来自某个大模型,而不是靠猜?论文解决的问题是什么?大模型生成文本越来越像人写的,传统“AI 内容检测器”靠统计模式去猜,很容易被分布漂移、提示工程和简单的改写攻击打崩。论文要解决的是:如何给模型生成的文本打上一个“几乎擦不掉”的水印,并且在数学上证明:想抹掉水印,需要付出很大的编辑代价。有何历史意义和性能突破?作者做了三件关键事:1. 给文本水印提出了一个严谨的理论
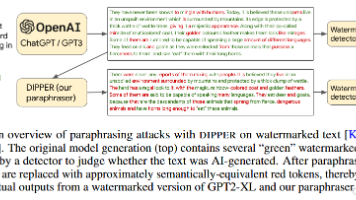
论文解决了什么问题?如何可靠地检测大模型生成的文本,尤其是在对方故意“洗稿”之后。作者证明,只要有一个足够强的改写模型,就能让当前主流检测器几乎“集体失效”,包括水印、DetectGPT、GPTZero、OpenAI 的 classifier 等。有何历史意义和性能突破?- 作者训练了一个 11B 参数的语篇级改写模型DIPPER,在保证语义几乎不变的前提下,让 DetectGPT 的检测准确率