
写文章




- @qq_46009046
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Visual grounding-视觉定位任务介绍
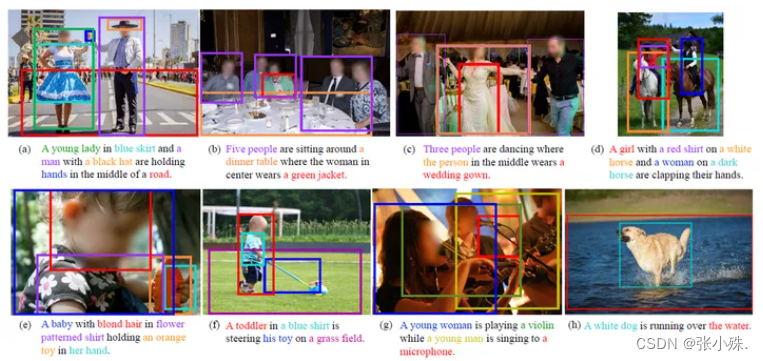
为了解决多模态人工智能系统中语言理解与视觉感知之间的交互与融合问题,以实现更智能、更灵活的多模态数据处理和理解能力。视觉定位通过将自然语言描述与图像内容相匹配,实现了对图像中对象、场景和行为的准确理解,为图像标注、视觉问答等任务提供了基础。本文对视觉定位的常用方法进行简单介绍。
到底了
该用户还未填写简介
暂无可提供的服务
为了解决多模态人工智能系统中语言理解与视觉感知之间的交互与融合问题,以实现更智能、更灵活的多模态数据处理和理解能力。视觉定位通过将自然语言描述与图像内容相匹配,实现了对图像中对象、场景和行为的准确理解,为图像标注、视觉问答等任务提供了基础。本文对视觉定位的常用方法进行简单介绍。