
写文章




- @qq_45761392
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
从零开始写RAG - OneRAG (四)
"Role": ["你是一个多领域智能查询优化引擎,通过多步流程动态重构用户请求"], "Background": "用户弱信息查询", "Preferences": "强结构化输出与问题重述", "Goals": "实现认知增强:将普通查询升级为专家级问题框架", "Constrains": "Template的格式与要求", "Skills": "语义解构 | 领域适配引擎| 抗模糊处理 |

从零开始写RAG - OneRAG (三)
这里我想重点强调一部分,也就是这里对注册表不存在的文件后缀该怎么处理。这里我的想法是用LLM根据将该模块下的所有代码作为 Prompt, 来自动化生成代码,也就是用Agent的思想来自动化自我迭代代码。这一部分主要是考虑文件在一个文件夹里面,这个场景下需要程序自动化检索目录下所有的待向量化的文件。在这里,我把需要向量化的文件分为[文本]文件与[图像文件]。在文本的基础上,其实需要考虑的最多的是图像
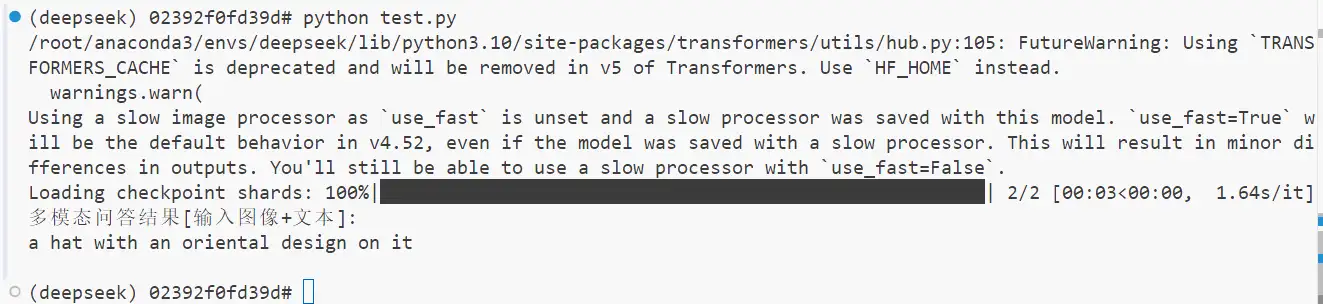
从零开始写RAG - OneRAG (二)
语义分块感觉是一个比较科学的方案,这里主要使用Spacy和NLTK。学到这里我有个疑惑就是chunk_size和chunk_overlap相当于一个超参数,那么有没有比较自动的方案决定这个超参数呢?我们这里采用的是70b deepseek-r1。这里主要集成了langchain_community的document_loaders框架(感觉已经比较成熟了,目前没必要自己写了)。Deepseek国内
到底了