
写文章




- @qq_43671025
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
大模型学习-基础篇(六):LoRA的版本改进
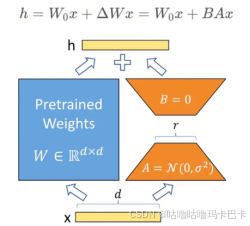
总的来说,LoRA改进的方向主要还是逼近全量微调的结果去努力,无论从权重初始化,梯度下降策略,模型层更新策略等角度出发,本质上都是让新的权重更新趋势拟合全量微调的过程。
大模型学习-基础篇(六):LoRA的版本改进
总的来说,LoRA改进的方向主要还是逼近全量微调的结果去努力,无论从权重初始化,梯度下降策略,模型层更新策略等角度出发,本质上都是让新的权重更新趋势拟合全量微调的过程。
大模型学习-基础篇(六):LoRA的版本改进
总的来说,LoRA改进的方向主要还是逼近全量微调的结果去努力,无论从权重初始化,梯度下降策略,模型层更新策略等角度出发,本质上都是让新的权重更新趋势拟合全量微调的过程。
大模型学习-实践篇(一):简单尝试
大模型学习-基础篇大模型学习-实践篇大模型学习-理论篇大模型学习-踩坑篇大模型学习-面试篇本地部署LLMs运行环境,能够完成大模型的推理、训练、量化的部署。我是在服务器上进行部署的,相关配置如下:服务器系统:CentOS 7.7存储:约40T显卡:A800 * 2(单卡显存 80 GB)网络:校园网虚拟环境:docker + minicondamodelscope提供了部署所需的全部详细文档,这里

大模型学习-基础篇(六):LoRA的版本改进
总的来说,LoRA改进的方向主要还是逼近全量微调的结果去努力,无论从权重初始化,梯度下降策略,模型层更新策略等角度出发,本质上都是让新的权重更新趋势拟合全量微调的过程。
到底了