




- @qq_42374697
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
补充好文:怎样进行数据的对比分析?数据分析(1):对比分析法一文看懂对比分析方法转载自:大白话系列:分析方法之对比分析作者:风轻袖影翻来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。对比分析是数据分析中最常用、好用、实用的分析方法,它是将两个或两个以上的数据进行比较,分析其中的差异,从而揭示这些事物代表的发展变化情况以及变化规律。先看看思维导图:使用分析方法(和谁比)
转载自:xianjuke008链接:https://blog.csdn.net/xianjuke008/article/details/86613213补充,结合例子+图理解概念数据模型、逻辑数据模型、物理数据模型详解1.概念模型(CDM) 在了解了用户的需求,用户的业务领域工作情况以后,经过分析和总结,提炼出来的用以描述用户业务需求的一些概念的东西。 如销售业务中的“客户”和“定单”,还有就
数据获取通过网页源代码的观察,可以发现职位信息在‘window.SEARCH_RESULT ’之后,‘’</scrip t>‘’之前,所以我们可以根据这个写出对应的正则表达式:'window.__SEARCH_RESULT__ = (.*?)</script>'用 Json 库进行解析data = json.loads(re.findall('window.__SEARCH
分析方法与过程(选择的原则)以往对财政收入的分析会使用 多元线性回归模型和最小二乘估计方法来估计回归模型的系数,通过系数能否通过检验来检验它们之间的关系,但这样的结果对数据依赖程度很大,并且求得的往往只是局部最优解,后续的检验可能会失去应有的意义。因此本案例运用Adaptive-Lasso变量选择方法来研究。LassoAdaptive-Lasso变量选择方法Adaptive_lasso算法是近些年
https://zhuanlan.zhihu.com/p/255105477https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.18.3b3022faqoVnOw&postId=129318https://www.jianshu.com/u/63b7115ac4eehttps://blog.csdn.ne
SWOT是英文Strengths、Weaknesses、Opportunities和Threats的缩写,即企业本身的竞争优势,竞争劣势,机会和威胁。SWOT分析法(也称TOWS分析法、道斯矩阵)即态势分析法,20世纪80年代初由美国旧金山大学的管理学教授韦里克提出,经常被用于企业战略制定、竞争对手分析等场合。SWOT分析有其形成的基础。按照企业竞争战略的完整概念,战略应是一个企业"能够做的"(即
存货复合年增长率(Compound Annual Growth Rate,CAGR)是一项投资在特定时期内的年度增长率 CAGR=(现有价值/基础价值)^(1/年数) - 1 或 (end/start)^(1/# years)-1它是一段时间内的恒定回报率。换言之,该比率告诉你在投资期结束时,你真正获得的收益。它的目的是描述一个投资回报率转变成一个较稳定的投资回报所得到的预想值。
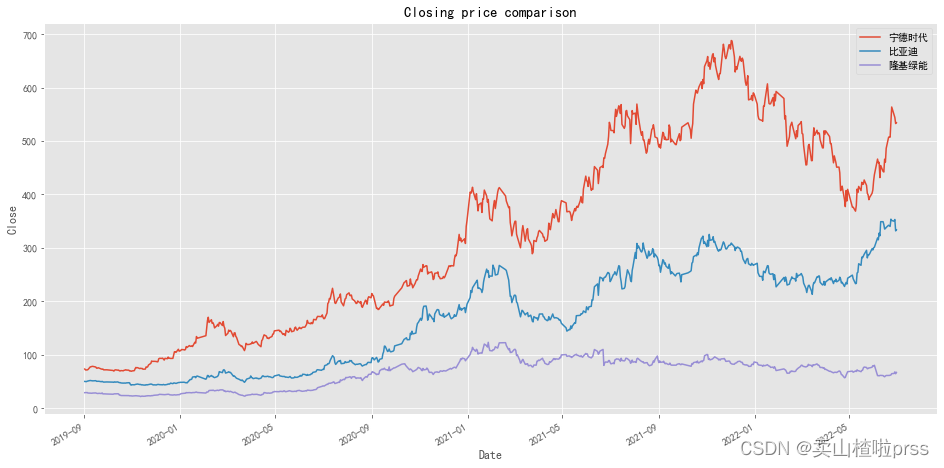
1、读入数据import matplotlib.pyplot as pltimport seaborn as snsimport numpy as npimport pandas as pdfrom pyecharts import options as optsfrom pyecharts.charts import Piefrom pyecharts.globals import ThemeT
补充好文:怎样进行数据的对比分析?数据分析(1):对比分析法一文看懂对比分析方法转载自:大白话系列:分析方法之对比分析作者:风轻袖影翻来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。对比分析是数据分析中最常用、好用、实用的分析方法,它是将两个或两个以上的数据进行比较,分析其中的差异,从而揭示这些事物代表的发展变化情况以及变化规律。先看看思维导图:使用分析方法(和谁比)
逻辑树分析法的目的,就是把复杂问题简单化,制定子问题解决方案即可。像树枝一样,将复杂问题拆解成若干简单子问题,即找出问题的主干,分解为相关的子问题,细化到最小单位; 针对每个子提出解决方案逻辑树有三种类型:问题树,假设树,是否树逻辑树分析法能够帮助我们理清思路,避免进行重复和无关的思考。分析步骤:第一步:确定需要解决的问题第二步:分解问题第三步:剔除次要问题第四部:进行关键分析第五步:制定方案推荐