- @qq_41895747
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
k-NN是最简单的机器学习算法之一,简单而言k-NN算法认为一个数据点很可能与它近邻点同属于一类,sklearn实现k-NN算法后面再复习一下,这次先学习OpenCV当中cv2.ml.KNearest_create()实现k-NN。步骤:得到一些训练数据指定K值,创建对象找到想要分类的新数据点的k个最近邻的点使用多数投票来分配新数据点的类标签画出结果图特别注意:OpenC...
独热编码这东西很有趣,和数字电路里面的格雷码有异曲同工之妙!其实也很正常,统计机器学习特别是自然语言处理方面的兴起正是引入了通信领域的数学模型,这段历史很有趣,可以看看吴军老师的《数学之美》。我们在处理机器学习数据的时候经常会见到离散特征的数据,例如水果的颜色、人名等,离散特征的挑战在于不是连续的方式,这导致很难用数字去描述,所以引入独热编码进行处理。独热编码,One-Hot编码,又称为一...
Floyd算法核心思想:找到第三个点代替使两点间的距离更短核心代码就五行://flody核心for(int k=0;k<n;k++)for(int i=0;i<n;i++)for(int j=0;j<n;j++)if(M[i][j]>M[i][k]+M[k][j])...
目录在Sarsa的基础上改进的sarsa lambda算法Sarsa存在的问题改进方法2:Sarsa Lambda参考开始每天被老师抓着写周报,以后想摸鱼都摸不了,心态baozha……在Sarsa的基础上改进的sarsa lambda算法算法流程和数学推导就不写了,弄清楚lambda的含义:如果 lambda = 0, Sarsa-lambda 就是 Sarsa, ...
在这个AI技术日新月异的时代,我们正见证着前所未有的创新与变革。尤其是在视觉内容生成领域(AIGC,Artificial Intelligence Generated Content),技术的每一次飞跃都意味着更加逼真、创意无限的数字艺术作品的诞生。自动生成内容的愿景日益成为现实。视觉领域,尤其是在图像和视频生成技术的进步,正引领着创意产业进入一个崭新的纪元。从消费者能够体验的个性化媒体到企业需求

最近强化学习在Diffusion Models得到了越来越多广泛的应用,本专栏将系统性地介绍当前Diffusion Models中实用且前沿的技术进展。

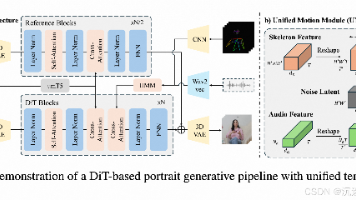
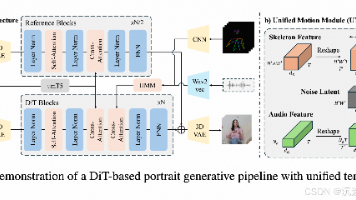
本文提出了一种基于人类偏好对齐的扩散框架,用于生成高度动态和逼真的音频驱动肖像动画。通过构建专门的人类偏好数据集,并引入定向偏好优化和时序运动调制两大创新,解决了唇部同步、表情自然度和运动连贯性等关键挑战。该方法在UNet和DiT架构中均表现出优势,实验表明其显著提升了唇音同步精度和面部表现力,同时在人类偏好指标上优于现有基线。研究还发布了首个针对肖像动画的偏好数据集,为相关领域研究提供了重要资源
目录在Sarsa的基础上改进的sarsa lambda算法Sarsa存在的问题改进方法2:Sarsa Lambda参考开始每天被老师抓着写周报,以后想摸鱼都摸不了,心态baozha……在Sarsa的基础上改进的sarsa lambda算法算法流程和数学推导就不写了,弄清楚lambda的含义:如果 lambda = 0, Sarsa-lambda 就是 Sarsa, ...
本文提出了一种创新的人类偏好对齐扩散框架,用于生成音频和骨骼运动驱动的高质量肖像动画。该框架包含两个核心技术:1)针对肖像动画的定向偏好优化,通过构建人类偏好数据集优化生成结果;2)时间运动调制机制,将不同采样率的运动信号有效整合到扩散模型中,保持高频运动细节。实验表明,该方法在唇音同步、表情自然度和运动连贯性方面显著优于现有基线方法,同时提升了人类偏好评价指标。研究还发布了专门构建的肖像动画偏好
清华大学提出高效视频理解FastVID、多伦多大学提出长时间视频理解模型Vamba、杭州电子科技大学提出反事实推理多模态大模型Bench COVER