




- @qq_41554005
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章目录分组卷积(Group Convolution)原理用途常规卷积(Convolution)空洞(扩张)卷积(Dilated/Atrous Convolution)深度可分离卷积(depthwise separable convolution)标准卷积与深度可分离卷积的不同深度可分离卷积的过程深度可分离卷积的优点可变形卷积网络背景想法评价卷积神经网络中十大拍案叫绝的操作一、卷积只能在同一组进行
文章目录一、核心思想二、结构三、为什么需要反馈?四、RNN的问题五、解决方法呢?六、总结参考文献一、核心思想区别于普通神经网络,循环神经网络Recurrent neural network (RNN)不仅仅单独的取处理一个个的输入,前一个输入和后一个输入不是完全没有关系的。在某些任务中,需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。二、结构最简单的循环神经网络由输入层、一个隐藏
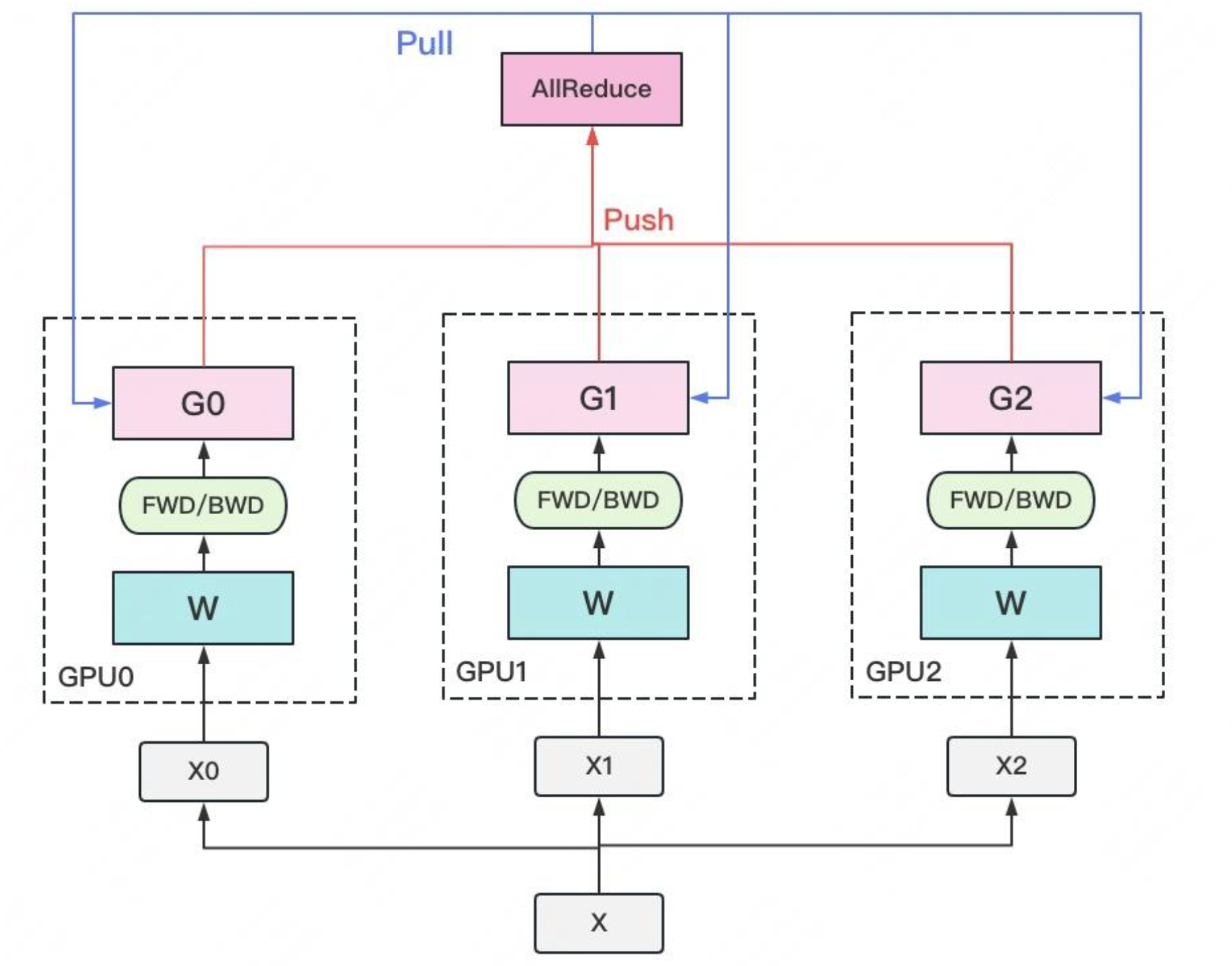
在DP中,每个GPU上都拷贝一份完整的模型,每个GPU上处理batch的一部分数据,所有GPU算出来的梯度进行累加后,再传回各GPU用于更新参数DP多采用参数服务器这一编程框架,一般由若个计算Worker和1个梯度聚合Server组成。Server与每个Worker通讯,Worker间并不通讯。因此Server承担了系统所有的通讯压力。基于此DP常用于单机多卡场景。异步梯度更新是提升计算通讯比的一
文章目录分组卷积(Group Convolution)原理用途常规卷积(Convolution)空洞(扩张)卷积(Dilated/Atrous Convolution)深度可分离卷积(depthwise separable convolution)标准卷积与深度可分离卷积的不同深度可分离卷积的过程深度可分离卷积的优点可变形卷积网络背景想法评价卷积神经网络中十大拍案叫绝的操作一、卷积只能在同一组进行
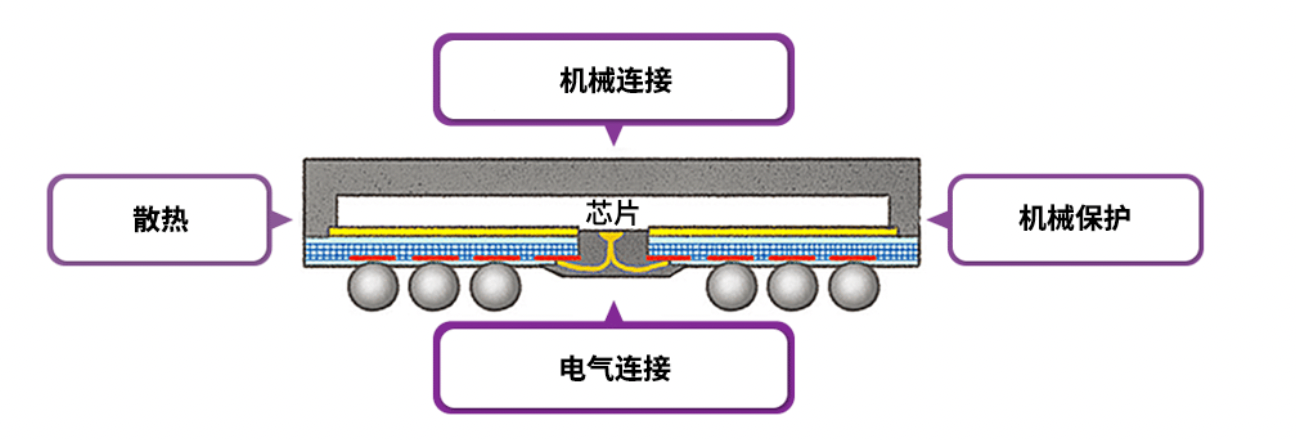
就像发动机用于为汽车提供动力一样,芯片键合技术通过将半导体芯片附着到引线框架(Lead Frame)或印刷电路板(PCB, Printed Circuit Board)上,来实现芯片与外部之间的电连接。塑料封装中,根据封装媒介的不同,又可进一步分为引线框架封装(Leadframe)或基板封装(Substrate)。[9]差评君,苹果的新芯片,真就是用两块芯片粘起来的 [10]知乎Vampire,片
文章目录分组卷积(Group Convolution)原理用途常规卷积(Convolution)空洞(扩张)卷积(Dilated/Atrous Convolution)深度可分离卷积(depthwise separable convolution)标准卷积与深度可分离卷积的不同深度可分离卷积的过程深度可分离卷积的优点可变形卷积网络背景想法评价卷积神经网络中十大拍案叫绝的操作一、卷积只能在同一组进行
文章目录零、前置知识一、LSTM目标二、LSTM的结构解析门结构的介绍遗忘门(forget gate)输入门(input gate)输出门(output gate)总结一下前馈结构流程三、LSTM变种四、解决问题的思路(从循环神经网络到LSTM)问题一:解决随时间的流动梯度发生的指数级消失或者爆炸的情况问题二:将信息装入长时记忆单元**论乘法:****论加法:**问题三:频繁装填带来的问题问题四:
文章目录一、注意力模型(Attention Model,AM)背景介绍二、注意力机制在神经网络建模中迅速发展的三个主要原因:三、Attention Model(AM)发展引入序列到序列模型Attention Model四、Attention Model(AM)分类基于多输入输出序列分类基于抽象层分类:基于计算位置分类基于多表示分类一、注意力模型(Attention Model,AM)背景介绍近段时
文章目录一、一个框架回顾优化算法1、SGD算法:评价:2、SGDM (SGD with Momentum)算法:评价:3、SGD with Nesterov Acceleration4、AdaGrad5、AdaDelta / RMSProp6、Adam7、Nadam二、关于Adam的分析1、Adam存在的问题一:可能不收敛2、Adam存在的问题二:可能错过全局最优解3、到底该用Adam还是SGD?
在DP中,每个GPU上都拷贝一份完整的模型,每个GPU上处理batch的一部分数据,所有GPU算出来的梯度进行累加后,再传回各GPU用于更新参数DP多采用参数服务器这一编程框架,一般由若个计算Worker和1个梯度聚合Server组成。Server与每个Worker通讯,Worker间并不通讯。因此Server承担了系统所有的通讯压力。基于此DP常用于单机多卡场景。异步梯度更新是提升计算通讯比的一