写文章




- @qq_41502855
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【bug解决】llama3微调bug解决
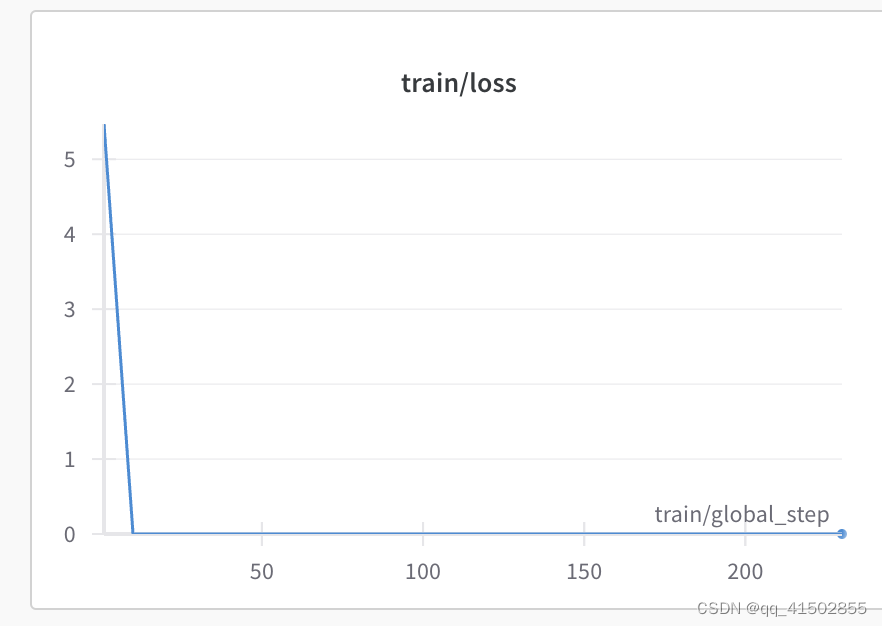
infnaninf。

【bug解决】deepspeed zero3 pretrain alpaca
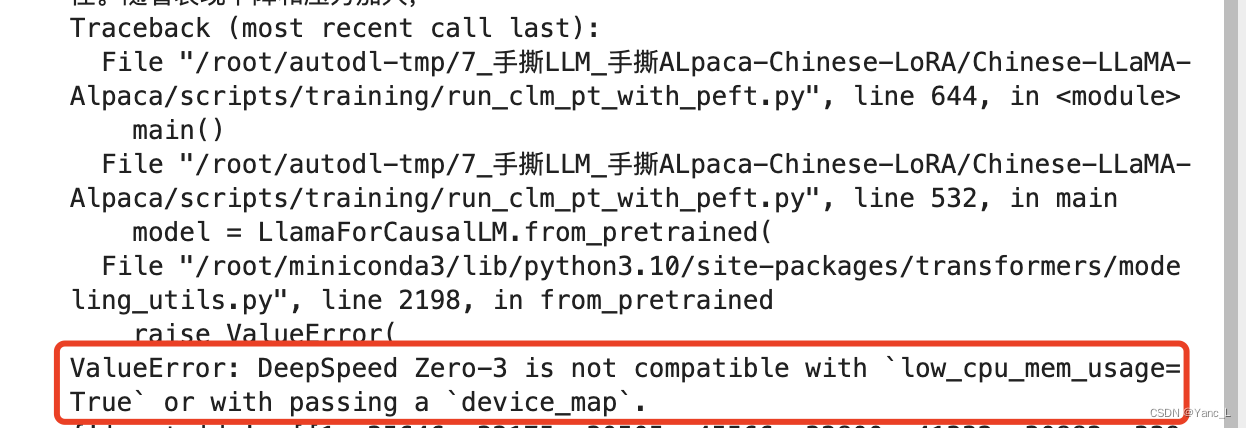
找到代码中的low_cpu_mem_usage=True改为False。
【bug解决】chatglm3推理 ValueError: too many values to unpack (expected 2)
chatglm3推理报错:too many values to unpack (expected 2)原因是transformers版本过高,修改为transformers==4.41.2。
【环境问题】pycharm远程服务器文件路径问题
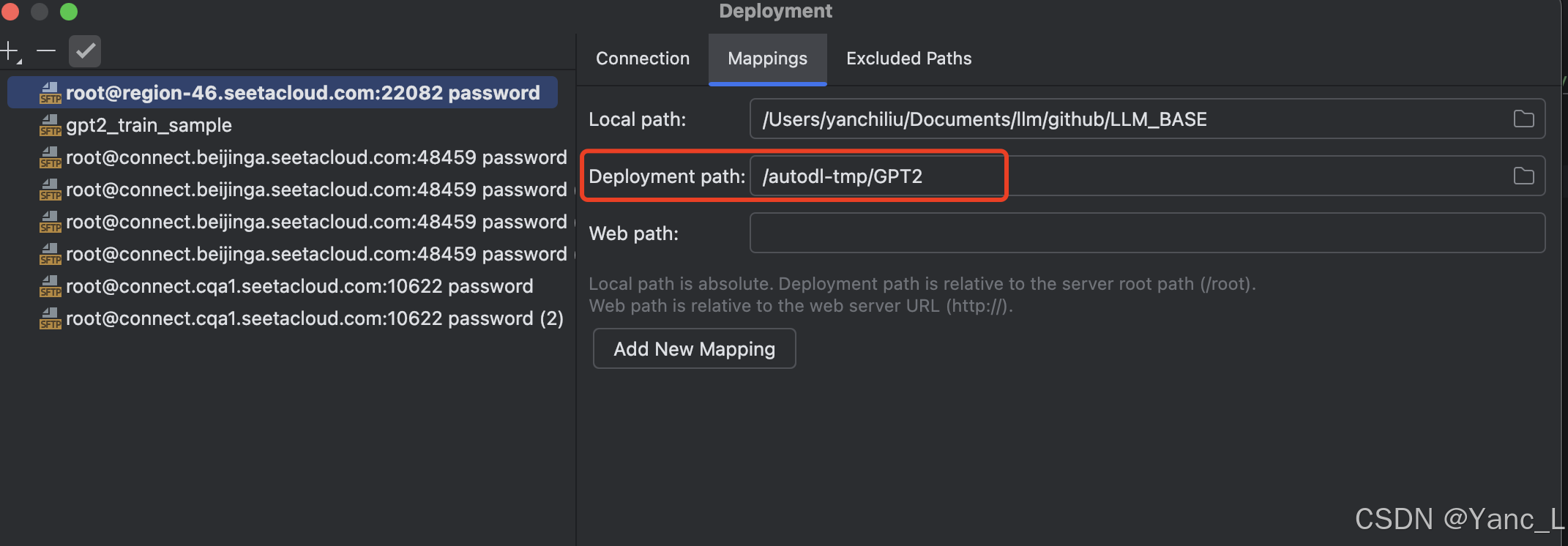
忘记修改Mapping中的映射地址导致upload文件后文件去到默认的tmp文件夹。
【bug解决】llama3微调bug解决
infnaninf。
【实践总结】vllm多卡推理
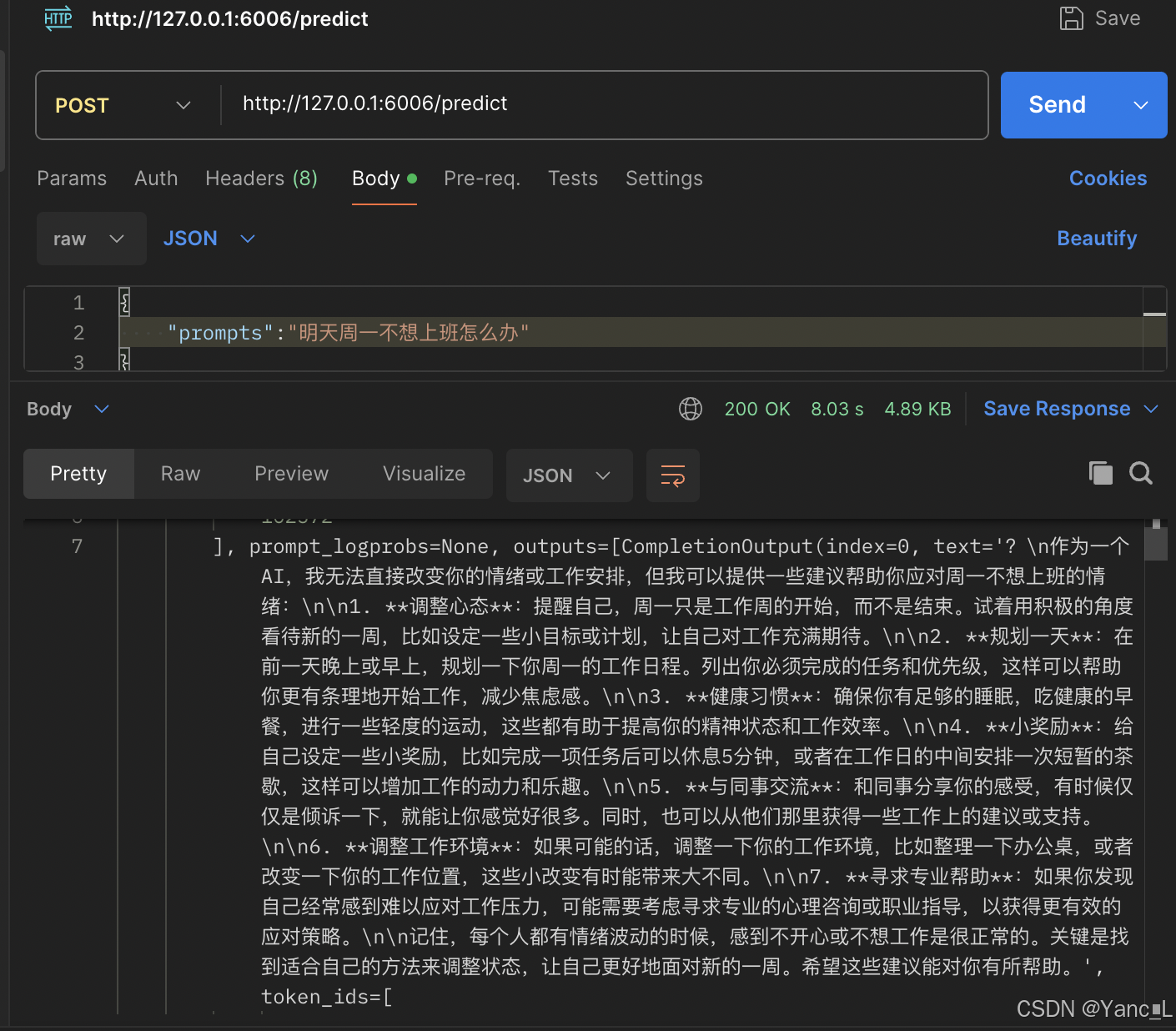
多卡推理,设置tensor_parallel_size=2,服务:Flask + gunicorn。多卡推理结果, 推理耗时11s。为什么多卡推理耗时更长了😵💫。环境:2* A100 40G。模型:qwen2-7B。
【实践总结】vllm多卡推理
多卡推理,设置tensor_parallel_size=2,服务:Flask + gunicorn。多卡推理结果, 推理耗时11s。为什么多卡推理耗时更长了😵💫。环境:2* A100 40G。模型:qwen2-7B。
vllm多卡部署Qwen2.5-72B-Instruct-GPTQ-Int4
3卡,tensor_parallel_size=3,tensor并行的数量一定要能被attentionheads整除。4卡,tensor_parallel_size=4,推理速度4s。双卡v10032G部署结果如下,推理时长16s。

【bug解决】vllm部署qwen
首次尝试vllm部署qwen遇到的一些问题。
【bug解决】Lora微调chatglm6b出现step10后loss持续为0
lora微调过程中出现loss持续为0。