




- @qq_40640228
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科;机器学习是一种偏向于技术的方法,研究目的包括模式识别、神经网络和深度学习;机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法,机器学习算法是一类从数据中自动分析获取规律并利用找到的规律对未知数据进行预测的算法。人工智能(是科学,为机器赋予视觉、听觉、触觉、推理等智能)机器学习(人...
一、数仓为什么要分层? 合理的数据仓库分层一方面能够降低耦合性,提高重用性,可读性可维护性,另一方面也能提高运算的效率,影响到数据需求迭代的速度,近而影响到产品决策的及时性。建立数据分层可以提炼公共层,避免烟囱式开发,可见一个合适且合理的数仓分层是极其重要。二、通用分层设计思路 ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者全量数据。作

一、快手大数据开发工程师面经作者:恶魔木魅妈妈咪链接:https://www.nowcoder.com/discuss/392528来源:牛客网一面(40min)1、自我介绍?2、Spark任务调度(源码)?SparkDeploySchedularBackend : 底层会通过SchedulerBackend方法针对不同种类的Cluster(StandAlone、Yarn、M...
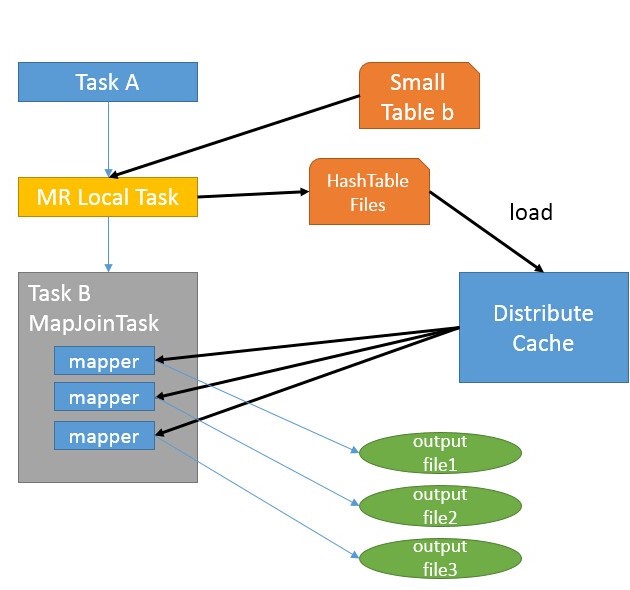
1、Fetch抓取 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。 在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本..
SQL Server 2012基于SQL Server 2008,其提供了一个全面的、灵活的和可扩展的数据仓库管理平台,可以满足成千上万的用户的海量数据管理需求,能够快速构建相应的解决方案实现私有云与公有云之间数据的扩展与应用的迁移。一、SQL Server 2012的新功能 1)AlwaysOn。 2)Columnstore索引。 3)DBA自定义服务器权限。 4)Wind...
1、Flink DataStreamAPIⅠ、DataStream API 之 Data Sources部分详解 source是程序的数据源输入,你可以通过StreamExecutionEnvironment.addSource(sourceFunction)来为你的程序添加一个source。 flink提供了大量的已经实现好的source方法,你也可以自定义source 通过实现s...