- @qq_36918149
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
做一个辅导小孩的机器人

本文介绍了一个大模型校验机制实现方案,通过RAG+向量库提升召回准确性的同时解决大模型幻觉问题。方案使用MaxKB和Dify平台搭建工作流,包含MaxKB API配置、Dify流程创建、HTTP请求模块设置和代码解释器编写等步骤。系统通过双模型校验机制(一个生成答案,另一个验证答案)来确保结果准确性,特别适用于病情诊断、投资决策等严谨场景。实施过程中需注意多模态模型调用耗时、节点调试和prompt

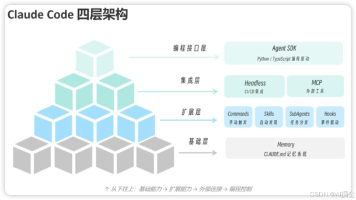
本文介绍了一个分层递进的AI架构系统。基础层由Memory记忆系统构成核心能力;扩展层包含Commands、Skills、SubAgents和Hooks四类组件,分别实现手动触发、自动发现、任务分发和事件驱动功能;集成层通过Headless和MCP实现与CI/CD及外部工具的连接;最上层提供Agent SDK编程接口,支持Python/TypeScript开发控制。整个架构遵循从基础能力到外部连接
本文介绍了基于MaxKB实现RAG方案的过程。首先分析了传统RAG在检索精度、文档处理等方面的痛点,提出了文本分割优化、混合检索等改进方法。然后详细讲解了在Ubuntu服务器上使用Docker部署MaxKB系统的步骤,包括端口映射、防火墙配置等注意事项,并分享了模型配置经验。最后总结了服务器配置不足导致的问题及解决方案。文章为后续MaxKB的实际应用奠定了基础,部署过程简洁高效,适合快速搭建RAG
本文介绍了如何使用无头浏览器技术进行动态数据抓取。首先解释了无头浏览器的概念及其优势,并详细说明了Selenium框架的配置方法,包括安装Chrome浏览器、驱动程序和必要的依赖项。通过测试代码验证了环境搭建的正确性。 实战部分以招聘网站为例,展示了如何分析页面结构并提取关键信息。文章提供了完整的Python代码示例,包含浏览器初始化、页面元素定位和数据抓取等关键步骤。这种方法特别适用于需要处理动

摘要:本文对比了传统RAG与Agentic RAG的差异。传统RAG采用线性流程,通过单次检索和生成回答简单事实性问题,但缺乏纠错能力。Agentic RAG则引入智能体概念,具有规划、多工具调用和迭代检索能力,适用于复杂开放式任务。关键区别在于Agentic RAG具备决策能力,可动态规划路径,整合多源信息。文章通过工作流程、核心特点和适用场景的对比,指出Agentic RAG是RAG技术的进化
本文介绍了如何利用MaxKB知识库系统提升AI解答数学题的准确性。通过将数学试题转换为Markdown格式并优化分段规则,构建知识库后测试不同检索方式(向量、全文、混合搜索)的效果。实验表明,该方法能显著提高答案准确率,并提供详细解题步骤。但同时也发现模型会回答知识库外的内容,这需要进一步优化。该方案有效解决了大模型在数学问题上的幻觉问题,为学生提供了更可靠的解题辅助。
向量数据库对比与选型指南 向量数据库是专为存储和检索向量数据设计的数据库系统,广泛应用于RAG、语义搜索、推荐系统等领域。主流产品包括Qdrant(高性能过滤)、Milvus(超大规模)、Chroma(轻量易用)、Weaviate(混合搜索)和Pinecone(全托管云服务)。选型需考虑数据规模、查询复杂度、运维成本等因素:千万级数据推荐Qdrant或Milvus;快速原型开发适合Chroma;混

总结:从AI技术栈全貌来看,基础模型、基础算法,个人及小公司是玩不起的,大公司才有对应人力、财力、算力 去做,个人更多的是要在应用场景上创新,几个关键的技术必须会:编码语言(Python、Java)、GPT4、stable diffusion、midjourney、Langchain、向量数据库

本文介绍了MCP架构中基于SSE(Server-Sent Events)的客户端实现方案。SSE模式通过HTTP协议实现服务器向客户端的单向实时数据推送,使用Starlette框架实现持久连接。文章对比了SSE与标准输入输出模式的差异,SSE模式支持实时更新、架构解耦,适合交互式应用。详细演示了从创建MCP服务器工具、建立Starlette应用到实现SSE客户端的完整流程,包括工具函数定义、SSE