




- @qq_35661896
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
可以直接用示例中的demo数据, 自己下载的数据也需要按照此格式组织好。
可以直接用示例中的demo数据, 自己下载的数据也需要按照此格式组织好。
参考:https://www.bilibili.com/video/BV1ybtBe1EkN?spm_id_from=333.788.videopod.sections&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localiza
2.5 和 3 中类对比。
1.BEiT(BERT Pre-training of Image Transformers)是一篇2021年发表在arXiv上的论文,提出了将BERT的思想应用于图像处理的方法。2.BEiT方法将输入图像切割成多个patch,随机mask掉一部分,并用一个可学习的编码替换被mask的部分。3.网络通过vision transformer结构预测被mask部分的内容,类似于分类任务。优化目标与数学
前置。
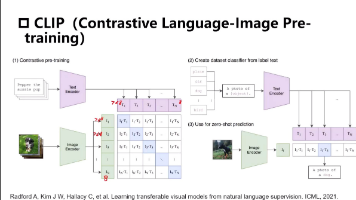
输入:用户提供的目标类别列表(如 [“dog”, “cat”, “car”])。关键点:类别可以是任意自然语言词汇,无需在训练集中出现过。
1.BEiT(BERT Pre-training of Image Transformers)是一篇2021年发表在arXiv上的论文,提出了将BERT的思想应用于图像处理的方法。2.BEiT方法将输入图像切割成多个patch,随机mask掉一部分,并用一个可学习的编码替换被mask的部分。3.网络通过vision transformer结构预测被mask部分的内容,类似于分类任务。优化目标与数学
参考链接:【理解】Beta贝塔分布Beta 分布归一化的证明(系数是怎么来的),期望和方差的计算β分布也是很重要的一个分布,其性质的探讨会继续更新~...
模式识别作业,书上只有一维正太变量的贝叶斯估计法的推导过程;这里给出多元正太分布下的贝叶斯估计的推导过程。(本人比较懒,直接上图趴。。。)至此推导出了均值与协方差矩阵测估计量;可以与一元正太分布的结果做对比,发现有很高的相似性!数学之美就在于此嘿嘿嘿~(如推导过程中有错误欢迎广大网友指出!)...