- @qq_30534253
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
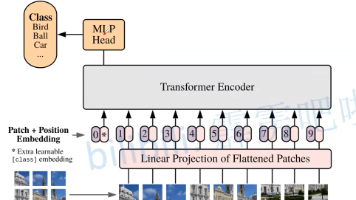
本文介绍了ViT和Swin Transformer两种基于Transformer的视觉模型。ViT通过将图像分割为patches,添加class token和位置信息后输入Transformer Encoder进行处理。Swin Transformer则针对目标检测任务改进,采用层次化特征图和窗口注意力机制,通过W-MSA和SW-MSA交替计算,在降低计算量的同时保持窗口间信息交互。两种模型都成功
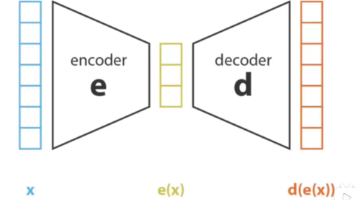
例如你的数据集有花和草,在之前的时候,模型会告诉你e(x) 100%是花,但是e(x)变成概率之后,模型告诉你,e(x)有0.8的概率是花,0.2的概率是草,那么就可能会生成一张带草的花;2.尽可能使p(z)和p(z|x)是平滑的,使p(z)平滑也就是让先验分布平滑,也就是为了确保任意的x都能有一个合理的输出,而不是出现一个从没有出现的x,就会落入z中的一个孤立的点,从而生成无意义的图片;使p(z
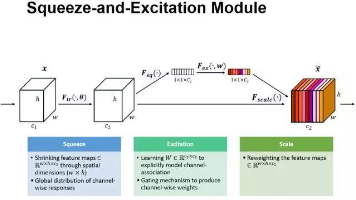
本文主要探讨了SENet和CBAM注意力机制在深度学习中的应用,以及HybridSN网络在高光谱图像分类中的实现。首先详细解析了SE模块的三步操作(Squeeze、降维升维、特征重标定)及其在ResNet中的集成方式。然后介绍了HybridSN网络的3D/2D混合卷积结构,并分析了3D卷积的特点。最后针对训练中的分类结果波动问题,指出需规范使用model.eval()函数,并提出通过添加注意力机制
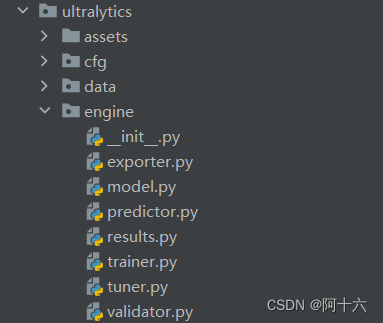
YOLOv10 训练时loss是nan,训练时显示页面太小。将self.amp = bool(self.amp)# as boolean。找到下载的ultralytics包中的trainer,打开。找到# Check AMP下的代码。在下一行增加self.amp = False即可。将workers设置为0即可。