




- @qq_21201267
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
是一个快速且易于使用的库,用于 LLM 推理和服务。如果不能连接 huggingface,设置。失业+面试中,今天学习一个新玩具。
本文基于 dify 和 vllm 部署的本地大模型,创建了一个修复python代码的 LLM 应用

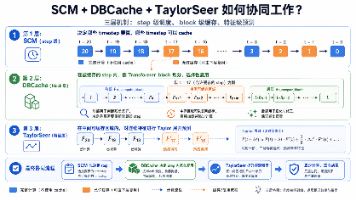
不同cache-dit版本 API 可能有小差异。下面是通用写法,如果你的版本支持import osif DEVICE!= "cuda":MODEL_ID,pipe,),.2fs")")CacheDiT 的核心不是“魔法加速”,而是利用扩散模型推理过程中的一个结构性冗余:相邻 denoising steps 的中间特征高度相似。DBCache:Transformer block 级别缓存,减少重复
两者并不是简单的“谁更强”关系,而是代表了当前大模型发展的两条重要路线:一条是面向高端闭源工作流智能体,另一条是面向高性能、低成本、可部署的开放权重模型。而 DeepSeek-V4 则突出开放权重、MoE 架构、1M 超长上下文和长文本推理效率,在竞赛型编码、数学推理和开放模型生态方面具有较强吸引力。整体来看,GPT-5.5 更强调真实工作流中的代理式执行能力,尤其适合编码、数据分析、在线研究、文

利用 timestep embedding 感知相邻 denoising step 的输出变化;变化小时复用缓存,变化大时完整计算。它最适合 DiT 类图像/视频/音频扩散模型,尤其是 denoising steps 较多、Transformer 计算占主要瓶颈的场景。生产里建议从开始,逐步调大,同时用固定 prompt、seed、分辨率和 steps 对比不开缓存、保守缓存、激进缓存三组结果。

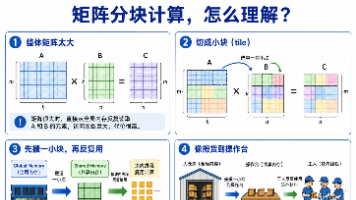
本文围绕 CUDA 矩阵乘法中的 Shared Memory 优化展开,通过 Naive 矩阵乘法与 Shared Memory Tiled 矩阵乘法的对比实验,分析不同TILE大小对kernel 性能的影响。实验基于 Tesla T4,测试矩阵规模包括TILE包括8、16、32、64。结果表明,Shared Memory 在大多数有效配置下能够明显加速矩阵乘法。
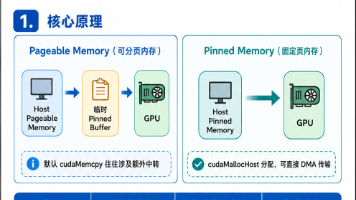
因此更合理的做法是:在大数据传输、批量推理、流式处理、异步拷贝等关键路径上使用 Pinned Memory,而不是把所有主机内存都改成 Pinned Memory。申请的固定页内存,它不会被操作系统换出,GPU 可以更直接地进行 DMA 传输,因此能够显著提升 Host 与 Device 之间的数据传输带宽。时,数据往往需要先经过一个临时的锁页缓冲区,再通过 DMA 传输到 GPU,过程相对多了一
│ 大模型推理并行体系 ││ ││ DP 数据并行 ││ - 多个完整模型副本 ││ - 分摊不同请求 ││ - 提高并发吞吐 ││ ││ TP 张量并行 ││ - 拆单层矩阵计算 ││ - 多 GPU 一起算同一层 ││ - 适合大 Dense 模型 ││ ││ PP 流水线并行 ││ - 按 Transformer 层切分 ││ - 不同 GPU 负责不同层 ││ - 适合超深、超大模型 ││

文章目录1. baseline2. 改进2.1 增加训练时间Digit Recognizer 练习地址相关博文:[Hands On ML] 3. 分类(MNIST手写数字预测)[Kaggle] Digit Recognizer 手写数字识别1. baseline导入包import kerasimport numpy as np%matplotlib inlineimport matplotlib.