




- @moonsims
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通 + 感 + 算 + 控 + 卫惯。人在“决策环”,不是“操作环”:通 + 感 + 算 + 控。单机无人机 ≠ 无人系统。:通 + 算 + 控。GCS 不做决策,只。
2026 年,与联合推出了 Spot 的多气体检测解决方案。这是 Spot 平台从"视觉巡检机器人"向"环境安全机器人"迈出的重要一步。气体浓度、报警信息和机器人位置会实时显示在 Spot 操作终端,并同步到 Blackline Live 云平台。一、整体系统架构。

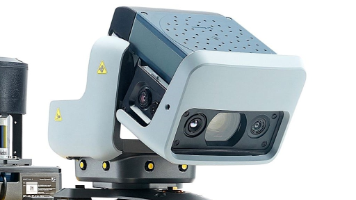
提供的就是机器人的"听觉"。它并不是传统意义上的麦克风,而是一套集于一体的智能声学载荷,可与 Spot Cam 2 配合完成多模态巡检。
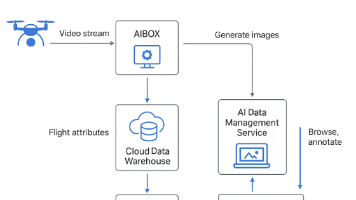
另外,和传统简单的BBOX不同,行业AI应用往往需要对检测目标实现轮廓检测以及量化、甚至是高精度的3D建模的需求。AIBOX基于现有的软件框架架构体系,提出边缘AI框架的服务,AIBOX完成取流、视频解码以及Scale或定义ROI,并且逐帧输出到共享内存,第三方独立的AI进程基于完成推理后输出结果,AIBOX框架负责OSD画框及标注,实现视频编码并格式上传。无人化应用除了人、车的识别以外还强调人、
从:测距模块升级为:✔全局漂移约束源。
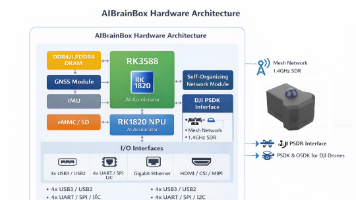
赋能电力巡检、工业检测、复杂环境自主飞行与具身智能研究AiBrainBox-V:重新定义工业无人机空间智能。

传统传感器可能会因为运动模糊或帧速率有限而错过快速移动的物体,而DVS可以检测到微秒级的变化,从而确保清晰捕捉快速运动的瞬间。较短的焦距提供更宽广的视野,使传感器能够捕捉场景中更多的运动,但可能会降低对远距离细微变化的灵敏度。与以固定间隔捕捉完整帧的传统传感器不同,这些仿生设备能够以微秒级的精度响应亮度变化,生成稀疏的、基于事件的数据,从而模拟我们人类视网膜处理视觉信息的方式。无论是蜂鸟振翅的瞬间

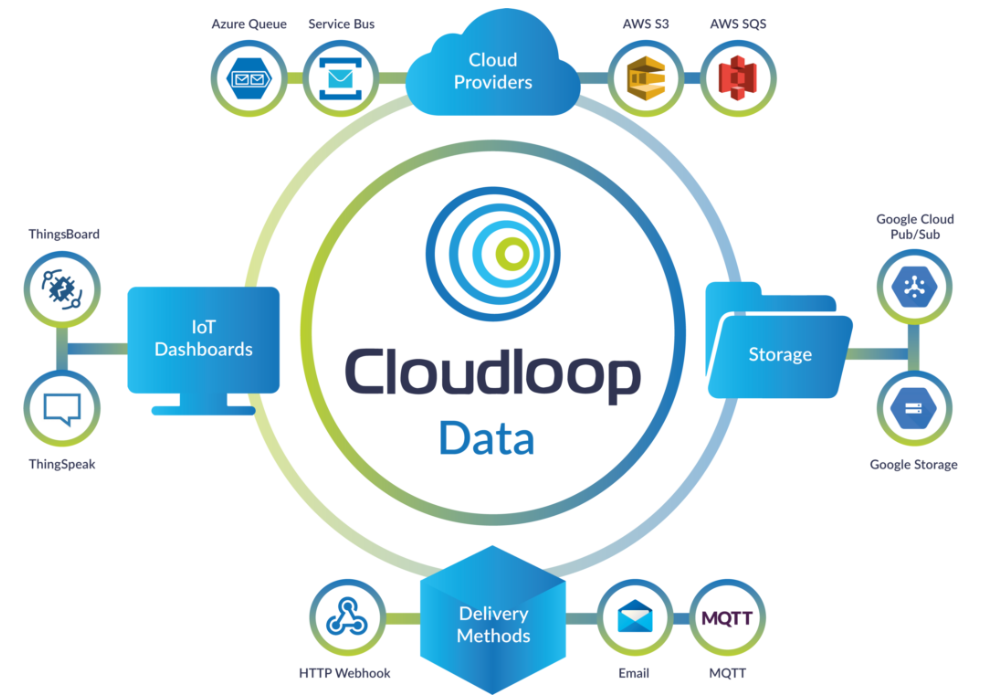
Cloudloop 设备管理器与我们支持 Iridium Certus 100 的 RockREMOTE 兼容,可轻松进行远程故障排除和对无人机和无人驾驶汽车等连接资产的监控,使您无需派遣工程师到现场或从远程或具有挑战性的位置恢复系统即可进行必要的维护和故障排除。Cloudloop Data 的设计以可扩展性和互操作性为首要考虑,提供多供应商平台集成,可与现有的云服务提供商、物联网仪表板和交付机制
Spot Cam+具备了云台可见光+红外相机,AiBrainBox-UGV需要外接类似设备。Spot Cam+ 实现了360°环视, AiBrainBox-UGV采用三目广角实现240°的环视。仅采用了激光雷达+GNSS,AiBrainBox-UGV融合了GNSS+激光雷达+可见光+工业级IMU多模态传感器融合,强调适应更复杂的地下空间。AiBrainBox-UGV实现了和机器狗/无人车的解耦,S

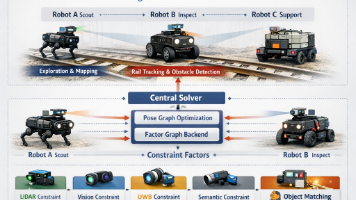
构建了一套面向GNSS拒止环境的空地协同自主系统,实现从多模态感知、多机器人融合定位,到任务分配与协同控制的全栈闭环能力。↓ 主流程(感知 → 决策 → 控制)UAV(全局) + UGV(局部)2026年5月20日 07:00。Factor Graph统一建模。↔ 横向(UAV ↔ UGV)↑ 反馈(执行 → 感知)