
写文章




- @m0_74420562
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
5090D本地部署基于Ktransformer框架的DeepSeek(踩坑版)
我是看九天老师的公开课,尝试使用单卡5090D+512G运行内存去跑一遍DeepSeek。以下是我使用最新显卡部署时踩得坑。模型为:R1 Q4_K_M1.Ktransformer全称(Quick Transformers)可以在模型运行过程中灵活的将专家模型加载到CPU上,同时将MLA/KVCache卸载到GPU上。2.Unsloth动态量化,通过内存分担显存的方法保证R1 Q4_K_M的运行,并
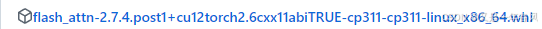
5090D本地部署基于Ktransformer框架的DeepSeek(踩坑版)
我是看九天老师的公开课,尝试使用单卡5090D+512G运行内存去跑一遍DeepSeek。以下是我使用最新显卡部署时踩得坑。模型为:R1 Q4_K_M1.Ktransformer全称(Quick Transformers)可以在模型运行过程中灵活的将专家模型加载到CPU上,同时将MLA/KVCache卸载到GPU上。2.Unsloth动态量化,通过内存分担显存的方法保证R1 Q4_K_M的运行,并
5090D本地部署基于Ktransformer框架的DeepSeek(踩坑版)
我是看九天老师的公开课,尝试使用单卡5090D+512G运行内存去跑一遍DeepSeek。以下是我使用最新显卡部署时踩得坑。模型为:R1 Q4_K_M1.Ktransformer全称(Quick Transformers)可以在模型运行过程中灵活的将专家模型加载到CPU上,同时将MLA/KVCache卸载到GPU上。2.Unsloth动态量化,通过内存分担显存的方法保证R1 Q4_K_M的运行,并
到底了