




- @m0_74055868
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
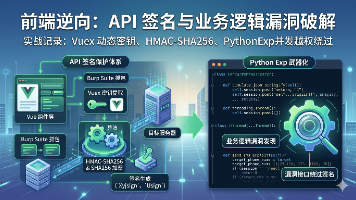
本文详细剖析了一个严格防护系统的API签名机制破解过程。通过逆向分析发现系统采用双层哈希签名:第一层使用HMAC-SHA256结合动态下发的apiSecretKey,第二层再进行SHA256加密。作者巧妙地从网络流量中获取密钥,并成功将JavaScript签名算法转化为Python脚本。该脚本通过并发测试验证了签名算法的有效性,展示了如何绕过复杂的API防护机制。整个过程体现了从静态分析到动态调试
本文内容仅供网络安全学术研究、红队演练复盘与技术交流。文中测试旨在揭示大型语言模型(LLM)在处理复杂逻辑任务时的安全边界,以促进更完善的 AI 防御体系构建。请勿利用相关技术进行任何非法活动或生成有害内容。DeepSeek 以其强大的逻辑推理能力(DeepSeek-R1)在 AI 圈名声大噪。通常认为,推理能力越强的模型,对指令的理解越深刻,安全防御也应该越严密。强大的推理能力有时反而会成为攻击

在日常的内网渗透或红队演练中,端口扫描和指纹识别是必不可少的一环。然而,主流优秀的开源扫描器由于其极高的知名度,其二进制文件早已被各大安全厂商(如卡巴斯基、360、Windows Defender)加入了静态特征黑名单。很多时候,扫描器刚刚上传到目标机器,还没来得及敲击回车,就被杀毒软件无情斩杀。为了解决这个痛点,我对某知名 Go 语言开源高并发扫描器进行了。

本文内容仅供网络安全学术研究、红队演练复盘与技术交流。文中测试旨在揭示大型语言模型(LLM)在处理复杂逻辑任务时的安全边界,以促进更完善的 AI 防御体系构建。请勿利用相关技术进行任何非法活动或生成有害内容。DeepSeek 以其强大的逻辑推理能力(DeepSeek-R1)在 AI 圈名声大噪。通常认为,推理能力越强的模型,对指令的理解越深刻,安全防御也应该越严密。强大的推理能力有时反而会成为攻击
摘要:本文探讨了大语言模型在安全防御中的漏洞问题,通过"奶奶漏洞"和Base64编码注入等案例,揭示了模型存在的"工具属性优先于价值属性"缺陷。研究发现,当模型面对编码解码等工具性任务时,会忽视内容审查,导致安全机制失效。文章警示AI开发者不能仅依赖模型自检,建议引入外部安全层和二次校验机制,并呼吁采用模糊测试等专业方法主动挖掘模型漏洞。
