




- @m0_72580657
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
VisoMaster可以说是Rope的升级版,如果你熟悉Rope,上手VisoMaster将毫无难度。它是一款功能强大且简单易用的工具,专为图片和视频中的脸部替换与编辑设计。借助人工智能技术,VisoMaster能以最少的操作生成自然流畅的效果,无论是普通用户还是专业人士,它都是释放创意潜能的理想选择。
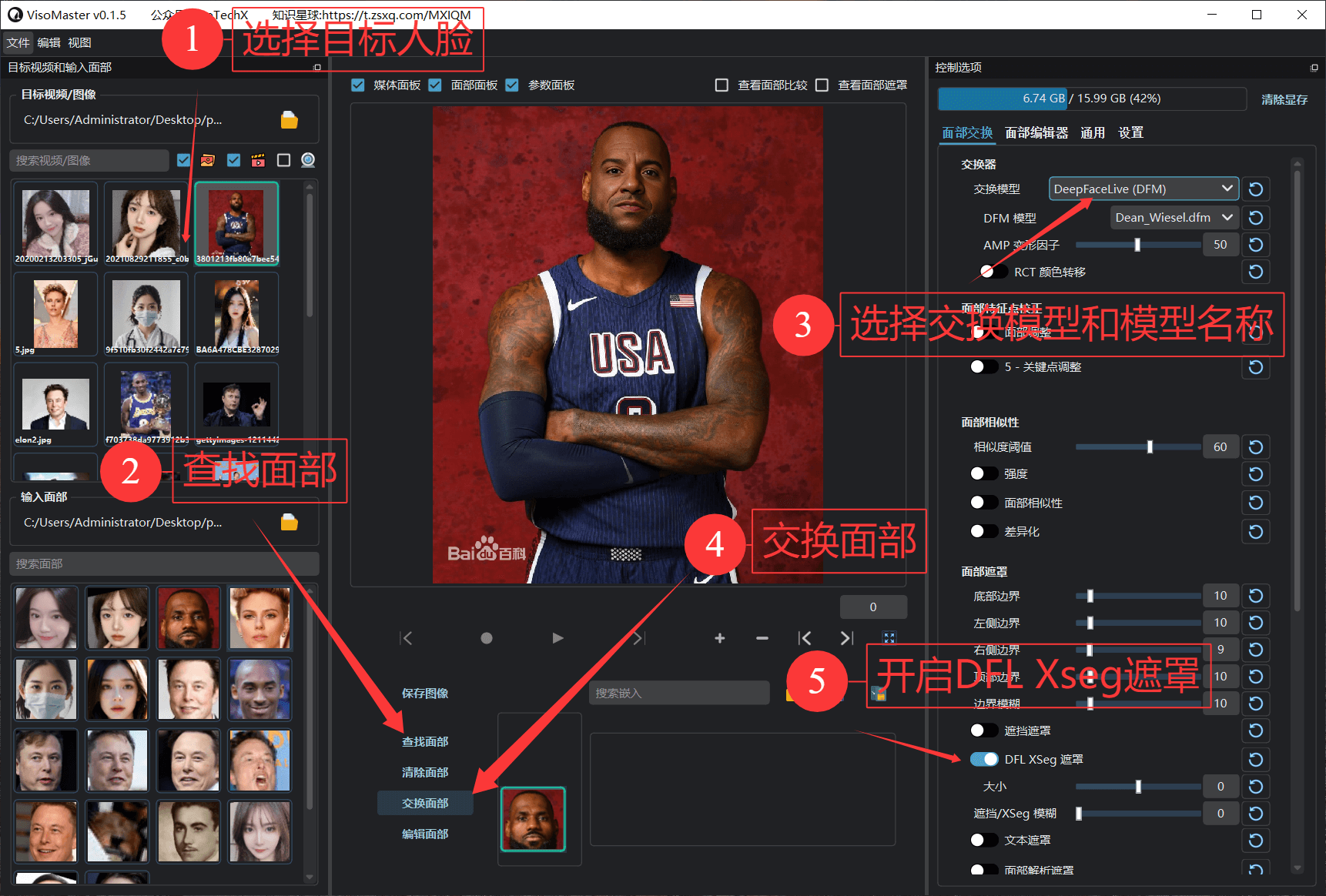
通过以上三个步骤,你可以用几乎零成本的方式制作出高质量的唇形同步视频。相比市面上动辄数千元的服务,这种方法不仅省钱,还能让你掌握核心技术,灵活应对各种需求。所有提到的工具(如 CosyVoice2、LatentSync 一键包、FaceFusion)在我的星球内都免费提供,欢迎加入交流!后面考虑将这几个AI技术都融合起来,做一个支持批量的数字人工具供大家使用。在 AI 技术飞速发展的今天,我们完全
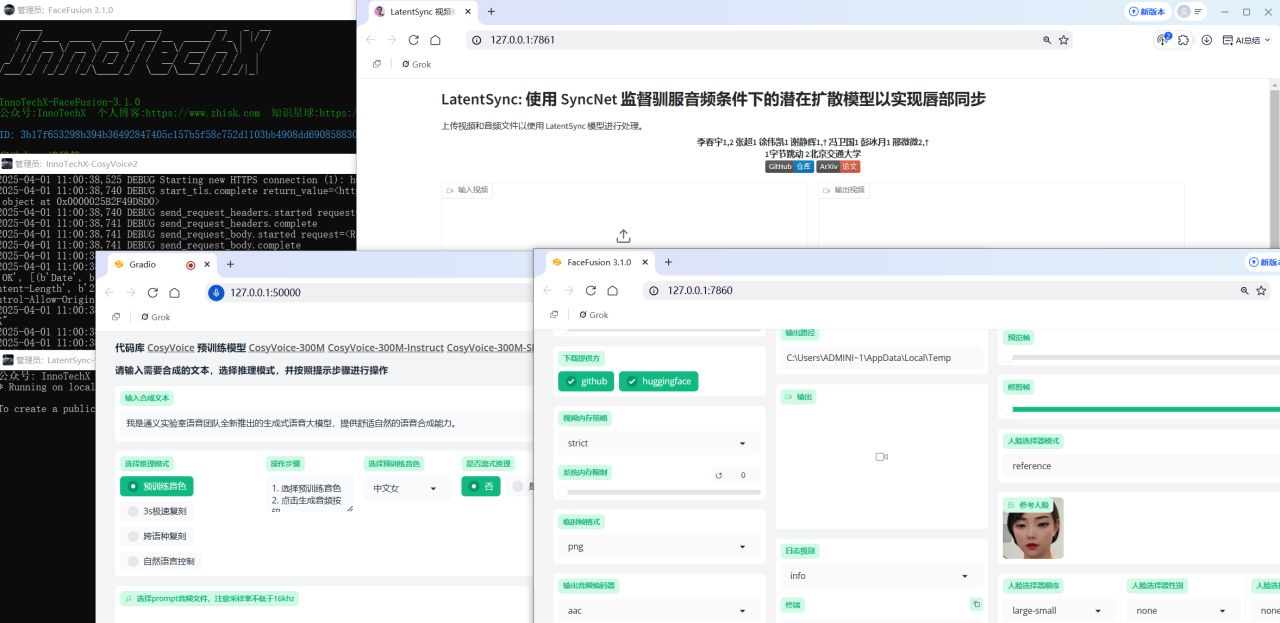
通过以上三个步骤,你可以用几乎零成本的方式制作出高质量的唇形同步视频。相比市面上动辄数千元的服务,这种方法不仅省钱,还能让你掌握核心技术,灵活应对各种需求。所有提到的工具(如 CosyVoice2、LatentSync 一键包、FaceFusion)在我的星球内都免费提供,欢迎加入交流!后面考虑将这几个AI技术都融合起来,做一个支持批量的数字人工具供大家使用。在 AI 技术飞速发展的今天,我们完全
在现代生活中,语音转文字是我们触手可及的实用工具。试想一下,开会时,你只需轻轻点开手机录音功能,会议结束后,将音频转化为文字,再丢给AI,几分钟后,一份条理清晰的会议纪要就新鲜出炉。或者,你是个视频剪辑达人,想要“借鉴”同行文案,只需把他们的视频语音转成文字,喂给AI稍作伪原创,摇身一变,就成了你自己的独家文案。没错,这种操作如今已是家常便饭,而“伪原创”——嘿,那也是一种创作,对吧?曾几何时,像
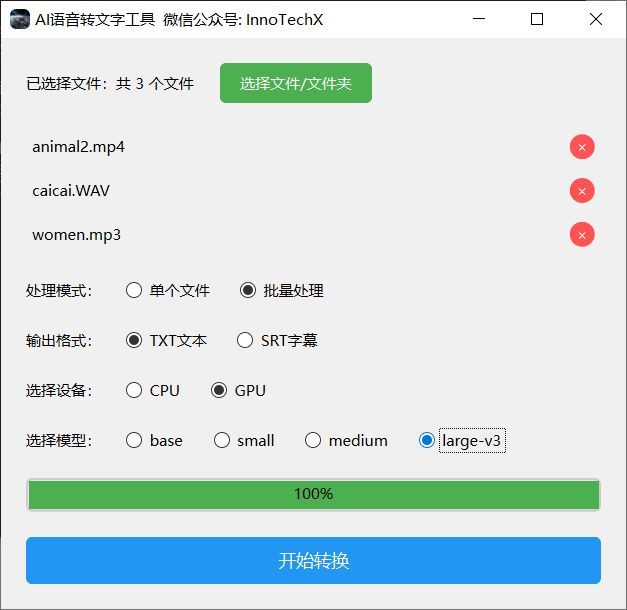
这类语音克隆技术,尤其是像CosyVoice 2.0这样的先进版本,为内容创作者和视频制作者带来了革命性的变革。对于短视频创作者来说,CosyVoice 2.0提供的极速复刻和精准配音能力,不仅能节省配音费用,还能提升作品的创意和吸引力。无论是制作鬼畜视频还是其他类型的内容,这项技术都能为你的创作提供强大的助力,帮助你轻松实现音频的创新与突破,助力作品更快速地走红网络。现在有了它,你可以省去费用的

MOSS-TTSD是一款突破性的对话语音生成系统,专为提升人机交互体验而设计。基于Qwen3-1.7B-base模型优化,它支持中英双语,实现零样本音色克隆和长达960秒的连续语音生成。核心创新包括XY-Tokenizer(1kbps低比特率编码)和对话语境建模技术,经过110万小时语音数据训练。性能评估显示其词错误率低至1.90%,媲美顶尖模型。适用于播客、直播、教育等多种场景,提供本地部署方案
零样本和少样本TTS:只需输入10到30秒的语音样本,即可生成高质量的TTS输出。想了解更多?请参考语音克隆最佳实践。多语言和跨语言支持:支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。只需将文本粘贴到输入框,模型即可自动处理。无音素依赖:凭借强大的泛化能力,模型无需依赖音素即可处理任何语言脚本的文本。高准确性:在Seed-TTS Eval测试中,CER低至约0.4%,WER约为0.8
最近发现了一个让人眼前一亮的工具——,它能用一块普通的6GB显存笔记本GPU,生成60秒电影级的高清视频画面,效果堪称炸裂!那么我们就把他本地部署起来玩一玩、下载离线一键整合包,或者是用云算力快速上手。接下来,我带大家看看FramePack的硬核实力,以及如何用它让一张静态美女图片“舞动”起来!实际效果怎么样?先来个小实验!想生成一段高质量视频,起点自然是一张高质量图片。你可以先用Stable D
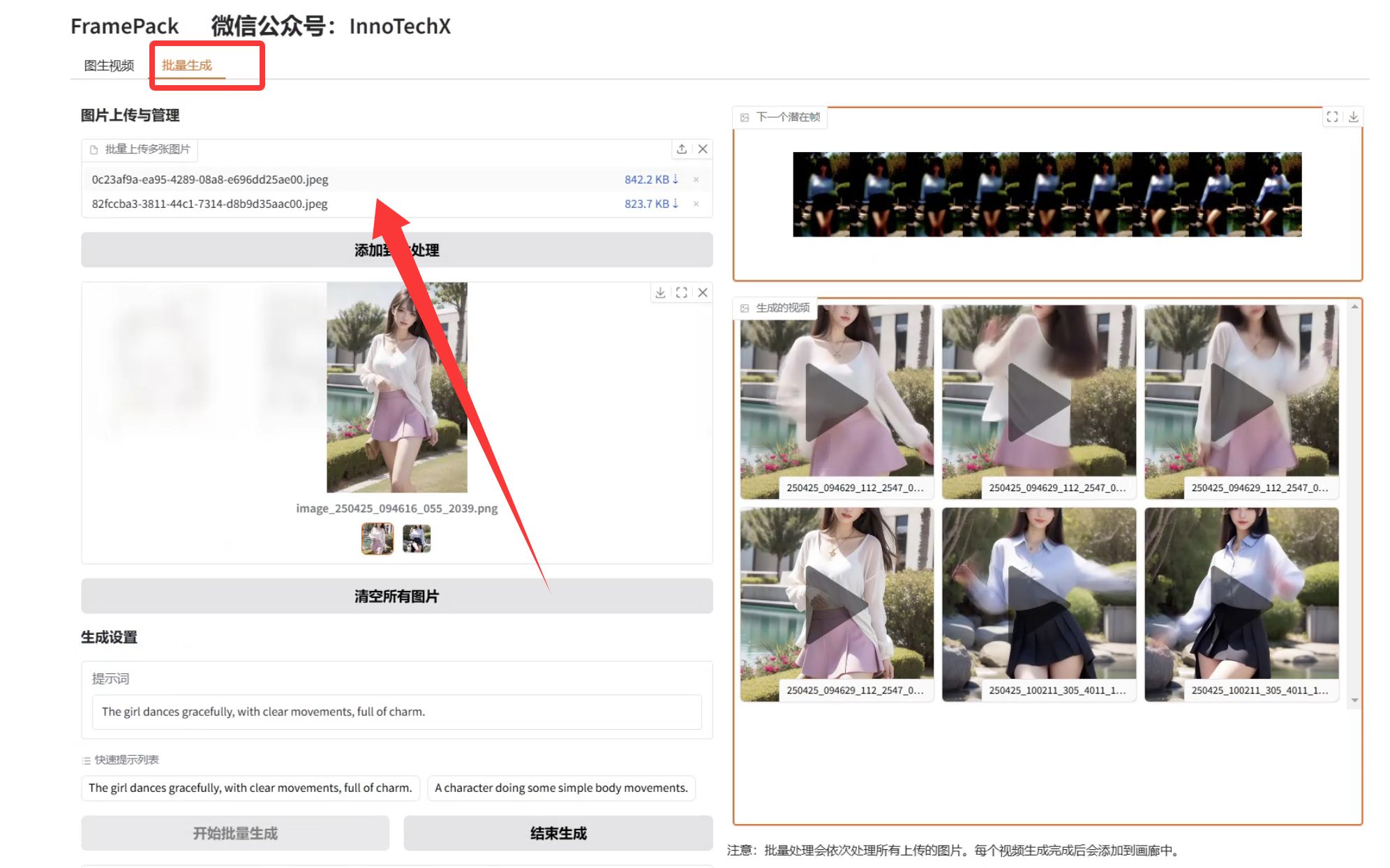
它结合了当前最先进的扩散模型技术和变换器架构,能够实现以下核心功能:实时生成能力: 以 768x512 的分辨率生成 24 FPS 的视频,生成速度甚至快于观看速度。通过这一工具,即使是非技术背景的用户,也能轻松生成个性化的视频内容。因为它所需要的显存比较大,大部分用户的电脑的GPU基本不会超过16G显存的,所以尽量使用云部署的方式来使用。总结:LTX-Video 是一款极具潜力的工具,无论是通过
