
写文章




- @m0_60599024
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
《AI+HW 2035:塑造下一个十年》论文核心重点解读
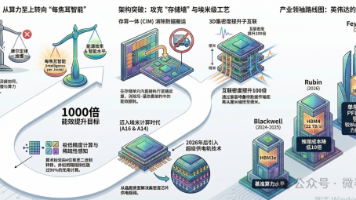
导读:2026年3月,由伊利诺伊大学厄巴纳-香槟分校(UIUC)、加州大学洛杉矶分校(UCLA)、斯坦福大学以及英伟达(Nvidia)、谷歌(Google)等27家顶尖学术机构与行业巨头联合发布的《AI+HW 2035:塑造下一个十年》(AI+HW 2035: Shaping the Next Decade)愿景白皮书,正式确立了一个跨越算法、架构、系统与可持续性的十年路线图。
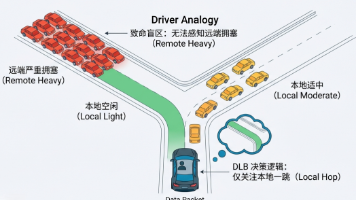
开启 DLB 后,为什么我的 GPU 还在等待?揭秘网络拥塞的“灯下黑”
摘要: DLB(动态负载均衡)在AI网络中常因"近视眼"特性导致局部最优但全局恶化,将流量导向远端拥堵链路。GLB(全局负载均衡)通过引入远端负载信息和非线性L2范数计算,放大拥塞"短板"效应,避免平均分配。工程上采用预计算LUT矩阵和惩罚因子,在芯片中实现纳秒级决策,强制绕行拥塞路径。AI网络需摒弃DLB单点优化,通过GLB全局视角和非线性映射实现端到端高
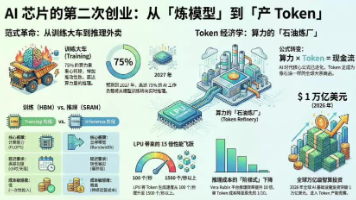
黄仁勋亲手打破GPU神话:AI芯片的第二次创业,从“炼模型“到“产Token“
AI芯片行业正经历从训练到推理的范式转变。2026年英伟达推出LPU推理芯片,标志其战略转型:通过200亿美元"掏空式并购"Groq,获得SRAM技术以解决推理场景的低延迟需求。市场格局随之剧变,亚马逊、谷歌等纷纷布局专用推理芯片,国产厂商则通过差异化路径寻求突破。随着AI应用普及,Token生产成为核心经济指标,算力竞争进入"炼油厂"模式——比拼的不再是模
到底了