




- @m0_47659929
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了在华为ModelArts平台(昇腾卡)上训练大模型的关键步骤:1)配置匹配的torch_npu插件版本;2)下载模型至指定路径;3)将数据集上传至llamafactory/data目录并配置数据文件;4)准备训练yaml配置文件(需根据硬件调整参数);5)编写启动脚本(注意单/多卡区别)。训练完成后需及时停止或删除实例以避免持续计费。作者指出相比一年前,当前平台易用性有所提升,但使
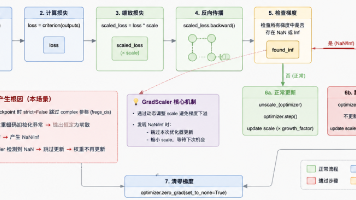
本文记录了作者在Text-to-CAD检索模型训练过程中遇到的严重问题及排查过程。模型训练表面正常(loss下降、保存checkpoint),但测试指标异常低下(R@1仅0.013%)。经排查发现:1)BRepEncoder权重出现大量NaN值,源于AMP混合精度中的GradScaler静默跳过NaN梯度更新;2)预训练权重加载时complex类型张量引发初始化问题。作者通过添加NaN检测、修复权
摘要:本文记录了在ModelArts平台进行模型微调训练的使用体验。平台界面经过优化,分类更清晰,新增MindSpeedLLM等官方镜像方便微调训练。详细介绍了资源配置选择(单卡32G/64G)、价格参考(8卡32G约150元/小时)及创建流程。特别提醒训练大模型需选择64G配置,并建议合理规划预算避免资源浪费。最后展示了环境创建后的工作目录和资源查看方法,为使用者提供实用参考。
摘要:本文介绍了在华为ModelArts平台(昇腾卡)上训练大模型的关键步骤:1)配置匹配的torch_npu插件版本;2)下载模型至指定路径;3)将数据集上传至llamafactory/data目录并配置数据文件;4)准备训练yaml配置文件(需根据硬件调整参数);5)编写启动脚本(注意单/多卡区别)。训练完成后需及时停止或删除实例以避免持续计费。作者指出相比一年前,当前平台易用性有所提升,但使
华为910B大模型微调实战指南 本文详细记录了在华为910B NPU服务器上微调Qwen14B/32B模型的全过程。关键要点包括: 容器配置必须使用--net=host模式,并正确挂载NPU设备驱动 软件版本严格匹配:Transformers,torch与torch_npu需配对安装 网络受限时可将LLaMA-Factory离线打包安装 虚拟环境常见问题排查:检查pip/python路径指向,避免
本文介绍了在英伟达服务器上搭建MySQL数据库的详细步骤。主要内容包括:1)通过Yum源安装MySQL 8.0社区版;2)解决安装过程中可能遇到的GPG Key验证问题;3)数据库初始化及root密码修改方法;4)启动服务和基础测试验证。文章强调拥有本地数据库是让大模型生成有效SQL查询的前提,并预告后续将分享如何将数据库与大模型能力结合使用。整个过程涵盖了从安装到配置的关键环节,为开发者提供了实
本文探讨在华为910B服务器上微调Qwen大模型前的准备工作,重点分析机器能力、基模选择与数据量的平衡关系。通过测试发现,在8卡64G配置下,使用DeepSpeed ZeRO-3优化可支持32B模型训练,显著提升资源利用率。同时指出模型规模与数据量的匹配关系:7B模型推荐2万条高质量数据,14B约4万条,32B约8万条,72B约15万条。强调高质量数据的重要性,建议根据实际资源、模型规模和数据质量
华为910B大模型微调实战指南 本文详细记录了在华为910B NPU服务器上微调Qwen14B/32B模型的全过程。关键要点包括: 容器配置必须使用--net=host模式,并正确挂载NPU设备驱动 软件版本严格匹配:Transformers,torch与torch_npu需配对安装 网络受限时可将LLaMA-Factory离线打包安装 虚拟环境常见问题排查:检查pip/python路径指向,避免
本文探讨在华为910B服务器上微调Qwen大模型前的准备工作,重点分析机器能力、基模选择与数据量的平衡关系。通过测试发现,在8卡64G配置下,使用DeepSpeed ZeRO-3优化可支持32B模型训练,显著提升资源利用率。同时指出模型规模与数据量的匹配关系:7B模型推荐2万条高质量数据,14B约4万条,32B约8万条,72B约15万条。强调高质量数据的重要性,建议根据实际资源、模型规模和数据质量
华为910B大模型微调实战指南 本文详细记录了在华为910B NPU服务器上微调Qwen14B/32B模型的全过程。关键要点包括: 容器配置必须使用--net=host模式,并正确挂载NPU设备驱动 软件版本严格匹配:Transformers,torch与torch_npu需配对安装 网络受限时可将LLaMA-Factory离线打包安装 虚拟环境常见问题排查:检查pip/python路径指向,避免