




- @liuhe2296044
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Deepseek》论文 1月26日LM可以看做是一种强化学习,state是当前prompt,action是从所有词典中选出一个token。RLHF 是让模型遵循标注者的偏好。LM模型和强化学习(一种训练智能体策略的框架)区别。论文出发点:想拥有复杂问题的推理能力:step by step来解决。(通过强化学习来激励语言模型,使其用于复杂问题的推理能力)之前是采用PPO,但是最近采用DPO,现在使用

per_token_logs和old_per_token_logps都是softmax再取log后得到的,每个元素都是负数,现在相减再e的对数,也就是原来的值相除,对应公式中。一个prompt采样多个output然后给不同的output不同的权重(advantage),提出一个新的token级别loss。②为什么πold用self.model生成,π也用self.model生成( 这不都是基线+l
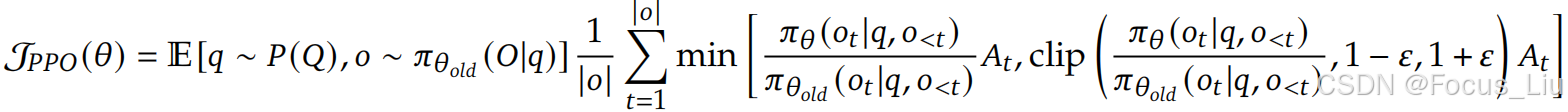
per_token_logs和old_per_token_logps都是softmax再取log后得到的,每个元素都是负数,现在相减再e的对数,也就是原来的值相除,对应公式中。一个prompt采样多个output然后给不同的output不同的权重(advantage),提出一个新的token级别loss。②为什么πold用self.model生成,π也用self.model生成( 这不都是基线+l
Deepseek》论文 1月26日LM可以看做是一种强化学习,state是当前prompt,action是从所有词典中选出一个token。RLHF 是让模型遵循标注者的偏好。LM模型和强化学习(一种训练智能体策略的框架)区别。论文出发点:想拥有复杂问题的推理能力:step by step来解决。(通过强化学习来激励语言模型,使其用于复杂问题的推理能力)之前是采用PPO,但是最近采用DPO,现在使用
集群:Mac:172.16.122.1Master:172.16.122.101Slave1:172.16.122.102Slave2:172.16.122.101第一步、安装CentOS7第二步、安装GUI:命令yum install NetworkManager-tui第三步、配置虚拟机的nat上网模式①更改虚拟机上网模式:改成【桥接模式-wifi】 ②...