- @ldcdata
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
它可以用于各种语义相关的任务,如语义角色标注、关系抽取、文本摘要、问答系统等。通过利用这个数据集,研究人员可以开发更加准确和高效的自然语言处理算法和模型,推动自然语言处理技术的不断进步。在数据内容上,Chinese AMR 数据集涵盖了多种来源的文本数据,包括新闻、讨论论坛、博客等。同时,为了丰富数据集的语义内容,它还可能引入了一些新的数据源,如来自特定文学作品或专业领域的句子等。这个数据集的目标
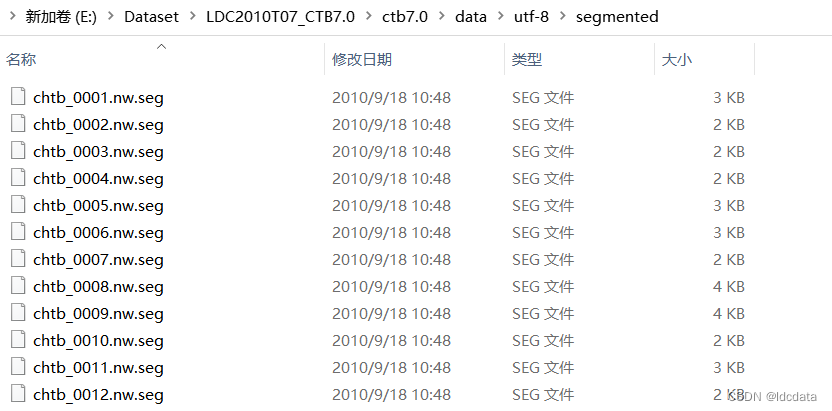
ctb7.0是一个树库数据集,其文件结构如下:
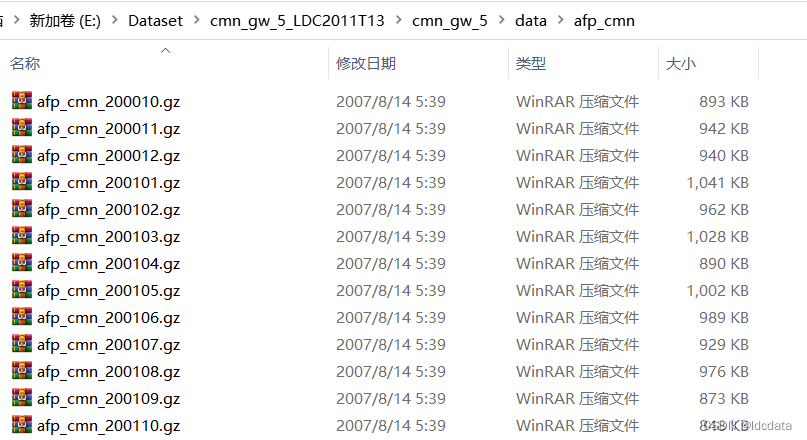
Chinese Gigaword是一个语音数据集,其文件结构如下:
ATIS3 Training Data”指的是与ATIS(Airline Travel Information System)数据集相关的第三版训练数据。训练数据(Training Data)在机器学习和深度学习中起着至关重要的作用。它是用来训练模型的数据集,通过让模型学习训练数据中的特征和规律,模型能够学会如何对新的、未见过的数据做出预测或分类。在ATIS3 Training Data中,包含了
ATIS3 Training Data”指的是与ATIS(Airline Travel Information System)数据集相关的第三版训练数据。训练数据(Training Data)在机器学习和深度学习中起着至关重要的作用。它是用来训练模型的数据集,通过让模型学习训练数据中的特征和规律,模型能够学会如何对新的、未见过的数据做出预测或分类。在ATIS3 Training Data中,包含了
Ontonotes 4.0是一个新闻数据集,其文件结构如下:
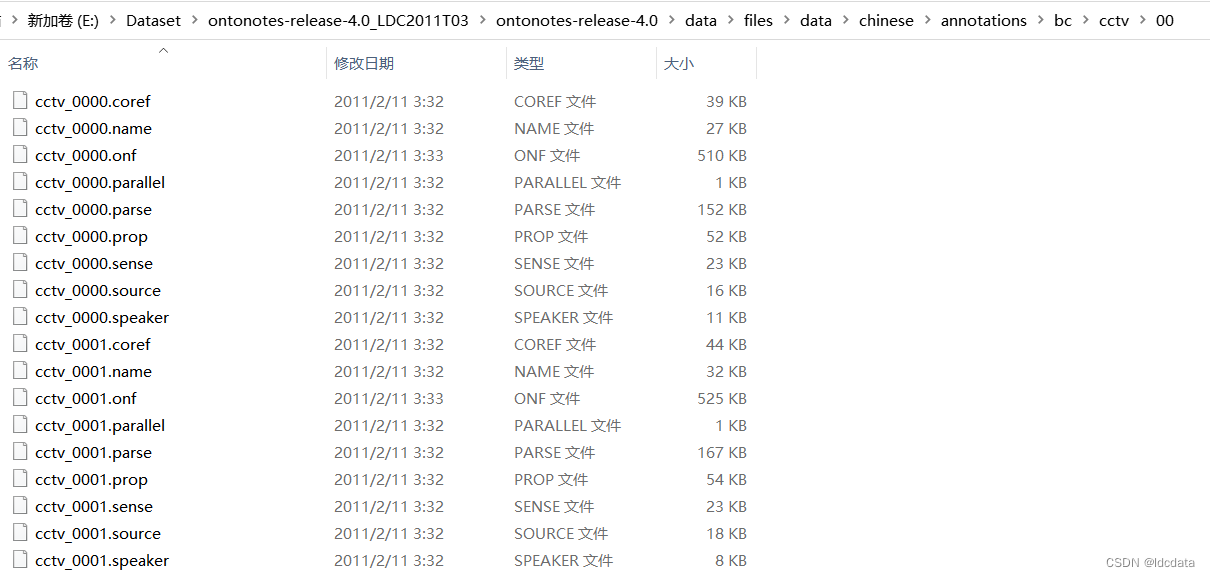
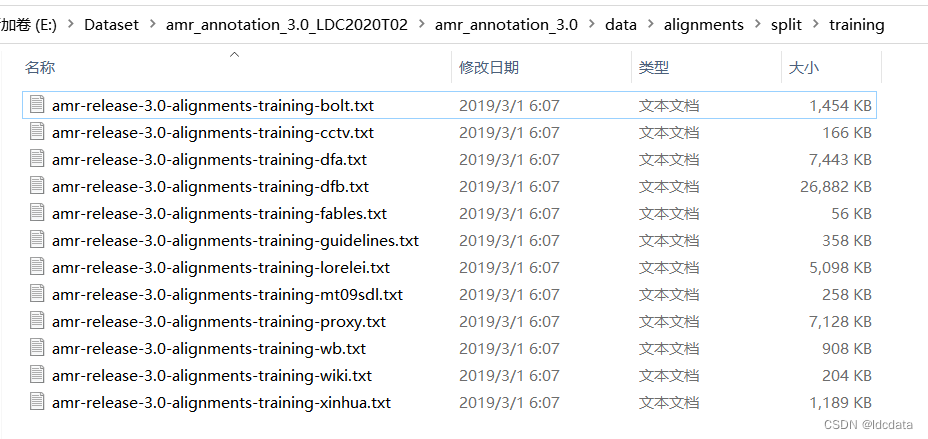
Rich ERE数据集常用于关系抽取任务,文件结构如下:
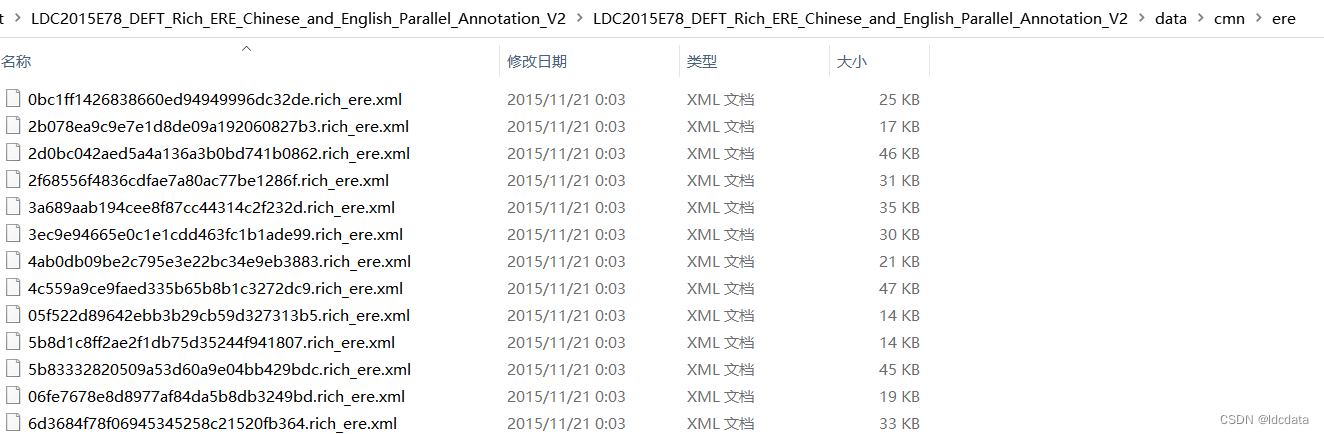
它是由美国国家情报总监办公室(Office of the Director of National Intelligence)赞助的一个项目的一部分,旨在推动自动内容提取技术的发展,以支持文本形式的人类语言的自动处理。实体标注指定了文章中的具体实体,如人物、组织、地点等,而实体关系标注则指定了这些实体之间的关系,如就业关系、成立关系等。除了实体和实体关系标注,ACE2004数据集还提供了其他信息,
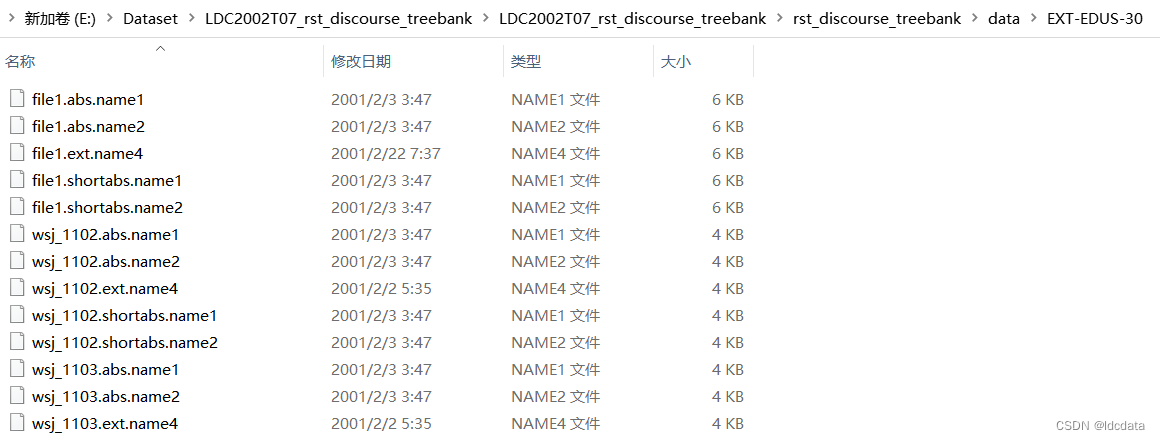
RST Discourse Treebank 是一个树库数据集,其文件结构如下:
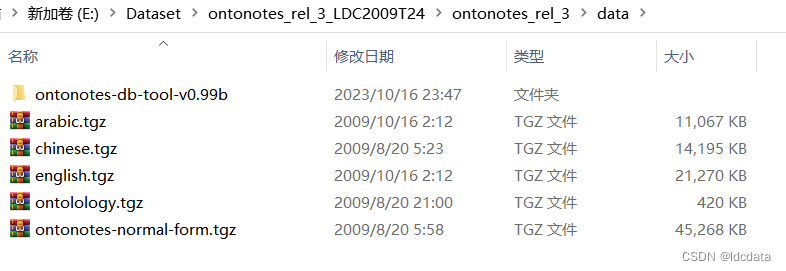
Ontontoes 3.0 数据集常用于文本任务,其文件结构如下: