




- @kl28978113
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在我们日常的运营活动中,在各个不同的运营阶段,经常需要对游戏的活跃、流水等进行预估。并且我们需要预估的不仅仅是最终的一个结果值,可能更需要的是完整的增长趋势,需要根据导入量,付费留存情况,去预测每一天的活跃、流水情况。这时候一个比较科学、简单的模型就比较关键了。本周就介绍一个笔者在工作中经常用到的一个预估模型,一个已经经过了多次优化和认证的模型。**该模型不仅仅可以预估一个游戏的流水活跃等走势..
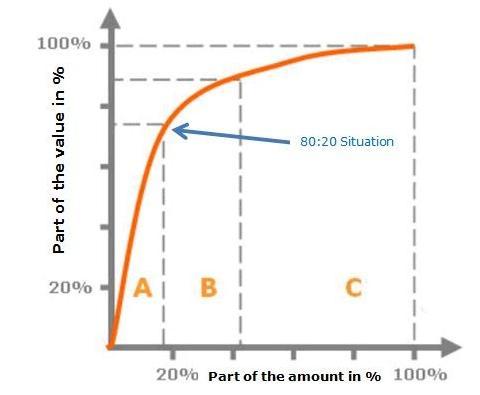
很多人都知道二八定理,即20%的人掌握着80%的财富。源出处是80/20帕累托法则,很有名的ABC分类法可以说是该法则的衍生。比如一共有100件商品,10件商品占销售总额的70%,20件商品占销售总额的20%,还有70件商品仅占销售总额的10%。于是你可以按照70%,20%,10%的销售额比重把产品分为ABC三类,然后把重点的管理资源放在A,把较少的资源分配给C或者砍掉部分C商品,以达到资源管理的
适用人群数据分析,机器学习,数据挖掘领域研究者。Python语言使用者。课程概述【数据分析与机器学习销冠课程,超100000名小伙伴加入】【连续多年荣获“最佳课程奖”,人工智能类“唯一”获奖课程,最佳合作伙伴】【课程同名配套教材《跟着迪哥学Python数据分析与机器学习实战》现已出版,加入课程免费送配套PDF版教材】课程特色:1、机器学习算法全面覆盖,每个算法均有配套项目实战!2、通俗易懂,用最接
本文所有数据指标的定义均按照国际规范重新梳理,并对传统游戏运营数据分析方法中的常用指标进行调整,使之更适合移动游戏这一新领域。统一的数据分析指标,有助于运营人员理解、分析用户行为,改进产品,制定运营策略,让数据化运营更有效率。一、用户获取(Acquistion)日新登用户数(Daily New Users,DNU):每日注册并登录游戏的用户数。解决问题:1....
这当然是积极的变化,但也助长了一种本能倾向,即让数据可视化成为了一种汇报时的必备“流程”,开始无目的地进行可视化,结果做出的图表差强人意,比如机械地把电子表格单元转换为图表,只能提供支离破碎的信息,或者无效却扰乱视听影响决策的信息,进而无法传达出完整的理念。当我们想表达过多类型的数据时,可以使用矩形树图,它展现同一层级的不同分类的占比情况,还可以同一个分类下子级的占比情况,每个矩形代表一个聚合类,

这是简易数据分析系列的第 5 篇文章。上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据全部爬取下来。前面我们同时说了,爬虫的本质就是找规律,当初这些程序员设计网页时,肯定会依循一些规则,当我们找到规律时,就可以预测他们的行为,达到我们的目的。今天我们就找找豆瓣网站的规律,想办法抓取全部数
一、用户获取(Acquisition)AARRR模型指出了移动游戏运营两个核心点:1) 以用户为中心,以完整的用户生命周期为线索2) 把控产品整体的成本/收入关系,用户生命周期价值(LTV)远大于用户获取成本(CAC)就意味着产品运营的成功移动游戏的运营会经历如下从投入到产出的循环过程:Acquisition用户获取(投入)Activation ...
一、用户获取(Acquisition)AARRR模型指出了移动游戏运营两个核心点:1) 以用户为中心,以完整的用户生命周期为线索2) 把控产品整体的成本/收入关系,用户生命周期价值(LTV)远大于用户获取成本(CAC)就意味着产品运营的成功移动游戏的运营会经历如下从投入到产出的循环过程:Acquisition用户获取(投入)Activation ...
本文所有数据指标的定义均按照国际规范重新梳理,并对传统游戏运营数据分析方法中的常用指标进行调整,使之更适合移动游戏这一新领域。统一的数据分析指标,有助于运营人员理解、分析用户行为,改进产品,制定运营策略,让数据化运营更有效率。一、用户获取(Acquistion)日新登用户数(Daily New Users,DNU):每日注册并登录游戏的用户数。解决问题:1....
在我们日常的运营活动中,在各个不同的运营阶段,经常需要对游戏的活跃、流水等进行预估。并且我们需要预估的不仅仅是最终的一个结果值,可能更需要的是完整的增长趋势,需要根据导入量,付费留存情况,去预测每一天的活跃、流水情况。这时候一个比较科学、简单的模型就比较关键了。本周就介绍一个笔者在工作中经常用到的一个预估模型,一个已经经过了多次优化和认证的模型。**该模型不仅仅可以预估一个游戏的流水活跃等走势..