
写文章




- @halloweenn1
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Reflexion: Language Agents with Verbal Reinforcement Learning论文讲解概括
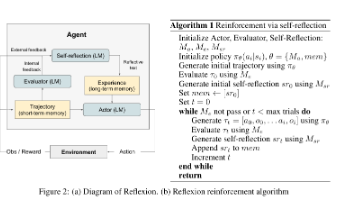
《Reflexion框架:语言反馈驱动的LLM智能体学习优化》 摘要:针对传统强化学习在LLM智能体中应用成本高的问题,Reflexion框架提出创新解决方案。该框架通过语言反馈替代权重更新,包含四个核心组件:行动者生成决策、评估者评分输出、自我反思模型生成改进建议,以及记忆系统存储反思内容。实验证明,在AlfWorld决策、HotPotQA推理和编程任务中,Reflexion显著提升智能体表现,
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free门控注意力论文阅读
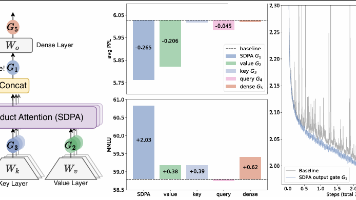
本文提出在标准softmax注意力机制中引入头部特定Sigmoid门控,最佳位置为SDPA输出处。该方法通过引入非线性增强模型表达能力,产生查询相关的稀疏门控,有效消除注意力沉没现象。实验表明,门控机制显著提升模型性能(降低困惑度、提高基准测试分数)和训练稳定性(减少损失尖峰、允许更大学习率),且计算开销低于2%。关键发现包括:头特定门控优于共享门控、乘法门控优于加法门控、查询相关稀疏性对性能至关
到底了