




- @guoke_tg
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的一种基于 Transformer Encoder 的预训练语言表示模型。其核心思想是通过双向上下文建模(deep bidirectional representation)来学习词的上下文相关语义,从而为下游任务(如问答、文本分类、NE

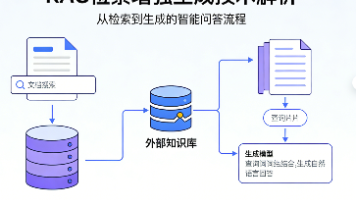
本文介绍了RAG(检索增强生成)技术及其完整实现方案。针对大语言模型的知识局限性和幻觉问题,RAG通过检索私有知识库增强回答准确性。文章详细讲解了RAG的三大核心模块:文档处理(包括PDF加载和智能分块技术)、嵌入模型(将文本转化为语义向量)以及向量数据库(Chroma的存储与检索)。重点阐述了如何根据文档内容特点优化分块策略,并提供了基于LangChain、Chroma、通义千问Embeddin
ResNet是何恺明团队在 2015 年 ImageNet 图像分类挑战赛中提出的深度卷积神经网络架构,一举斩获冠军。当时深层网络训练面临问题,网络深度超过一定阈值后性能会饱和甚至退化。为解决该痛点,ResNet 引入:通过跳跃连接让输入直接叠加到输出,使网络学习残差映射而非完整映射,既保留浅层特征,又降低深层训练难度。基于此结构,,在 ImageNet 上实现远超同期模型的分类精度,同时刷新检测

本文从零开始实现了一个基础 RNN 模型,包括参数初始化、前向传播、文本预测和模型训练等完整流程。通过实验可以发现,基础 RNN 在处理长序列时仍有局限(如梯度消失 / 爆炸、长期依赖捕捉能力弱)。改用 LSTM 或 GRU 等改进型循环神经网络增加注意力机制提升长序列处理能力使用预训练词向量替换独热编码尝试更复杂的优化器(如 Adam)和正则化方法通过从零实现的过程,我们能更深入地理解 RNN
LSTM 通过精妙的门控机制解决了 RNN 的长期依赖问题,成为处理文本等时序数据的强大工具。本文从原理出发,结合手动实现和 PyTorch 内置 API 的代码,展示了 LSTM 的工作流程。实际应用中,可根据需求调整隐藏层维度、序列长度等参数,进一步提升模型性能。
GRU(Gated Recurrent Unit,门控循环单元)是循环神经网络(RNN)的重要变体,专为解决传统 RNN 的 “长序列依赖” 问题而设计。这段代码是使用深度学习框架(基于 d2l 库)实现和训练一个循环神经网络(RNN),具体来说是 GRU(门控循环单元)模型,用于自然语言处理任务(如文本生成)。这段代码实现了 GRU(Gated Recurrent Unit,门控循环单元)的核心
LSTM 通过精妙的门控机制解决了 RNN 的长期依赖问题,成为处理文本等时序数据的强大工具。本文从原理出发,结合手动实现和 PyTorch 内置 API 的代码,展示了 LSTM 的工作流程。实际应用中,可根据需求调整隐藏层维度、序列长度等参数,进一步提升模型性能。
本文介绍了RAG(检索增强生成)技术及其完整实现方案。针对大语言模型的知识局限性和幻觉问题,RAG通过检索私有知识库增强回答准确性。文章详细讲解了RAG的三大核心模块:文档处理(包括PDF加载和智能分块技术)、嵌入模型(将文本转化为语义向量)以及向量数据库(Chroma的存储与检索)。重点阐述了如何根据文档内容特点优化分块策略,并提供了基于LangChain、Chroma、通义千问Embeddin
本次开发的核心任务是构建一个智能数据库查询系统接收用户的自然语言问题(如 “技术部有多少个员工?”);自动生成符合 MySQL 语法、匹配数据库表结构的 SQL 语句;执行生成的 SQL 语句并获取查询结果;将执行结果转化为简洁易懂的自然语言总结(先结论、再明细)。整个系统基于 LangChain 框架实现组件化编排,大模型选用 DeepSeek-chat,确保 SQL 生成的准确性和结果总结的可

GRU(Gated Recurrent Unit,门控循环单元)是循环神经网络(RNN)的重要变体,专为解决传统 RNN 的 “长序列依赖” 问题而设计。这段代码是使用深度学习框架(基于 d2l 库)实现和训练一个循环神经网络(RNN),具体来说是 GRU(门控循环单元)模型,用于自然语言处理任务(如文本生成)。这段代码实现了 GRU(Gated Recurrent Unit,门控循环单元)的核心