




- @goodparty
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
监督学习是机器学习的基础范式,通过带标签数据训练模型学习输入输出的映射关系。其核心矛盾在于:既要教会机器学习,又提前告知了答案。从原始查表法(记忆训练数据)到现代监督学习(学习映射函数),关键突破在于实现泛化能力而非机械记忆。监督学习解决了预测问题,但依赖标注数据且成本高昂。本质是从数据中提炼"从X预测Y"的通用公式,而非简单记忆答案对。

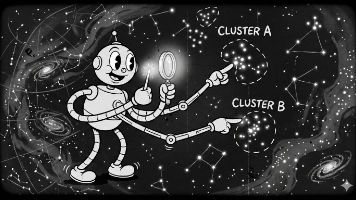
无监督学习是机器学习的重要范式,不依赖带标签数据,而是自主发现数据中的潜在结构和规律。主要任务包括聚类(相似数据分组)、降维(压缩高维数据)和异常检测。与监督学习不同,无监督学习不学习"X→Y"映射,而是探索"X之间的隐藏关系"。其优势在于不依赖昂贵标签数据,但代价是结果解释难度增加,学习目标不明确。核心思想是通过相似性度量和结构假设,让机器在无监督情况下自
摘要:本文介绍了使用Docker部署LiteLLM代理服务来调用DeepSeek模型的方案。通过docker-compose配置LiteLLM和Redis服务,并在config.yaml中设置DeepSeek API参数,可实现本地代理访问。尽管此方案能绕开Claude账号限制,但测试发现成本较高(1.5元/次),作者建议可考虑改用本地Ollama方案以降低成本。配置包含端口映射、模型参数设置和成
📝 摘要 PostgreSQL 的 Schema 是重要的架构工具,可实现命名隔离、权限控制和多租户支持。本文探讨了 Schema 设计的关键决策: 核心问题:Schema 应被视为"数据库中的数据库"而非简单文件夹,解决命名冲突和服务隔离问题 设计权衡: 单 Schema 简单但权限粒度粗 多 Schema 提供更好隔离但增加查询复杂度 应用场景: 按服务拆分适合微服务架构
正则化是防止机器学习模型过拟合的关键技术,通过在损失函数中添加惩罚项来限制模型复杂度。主要包括L1正则化(产生稀疏解)、L2正则化(权重衰减)和Dropout(随机丢弃神经元)三种方法。其核心思想是在模型拟合能力和泛化能力之间取得平衡:通过约束模型不能"太复杂",使其在新数据上表现更好。正则化虽然会略微增加训练误差和调参难度,但能显著提升模型的泛化性能。本质上是给模型加上&qu

深度学习优化器是改进梯度下降算法的关键组件。本文分析了优化器的演进历程:从基础SGD(易震荡收敛慢)到Momentum(引入惯性加速),再到Adam(结合动量与自适应学习率)。通过可视化对比和代码示例,揭示了各优化器的核心机制——SGD仅依赖当前梯度,Momentum积累历史梯度形成"惯性",Adam则通过动态调整学习率实现更稳定快速的收敛。虽然复杂优化器会增大计算开销,但其在

摘要: 学习率是深度学习中的关键超参数,控制模型参数更新的步长。过大的学习率会导致模型在最优解附近震荡或发散,过小则使收敛速度过慢。其本质是在收敛速度与精度间权衡,需根据梯度方向动态调整步长。常见策略包括固定学习率、衰减学习率和自适应方法(如Adam)。学习率的选择直接影响模型能否高效稳定地找到最优解,需平衡步长以避免训练效率低下或无法收敛的问题。

梯度下降是机器学习中最小化损失函数的核心优化算法,其本质是沿梯度反方向迭代更新参数。相比暴力搜索的高计算成本,梯度下降通过数学信息指引方向实现高效优化。主要变体包括:批量梯度下降(准确但慢)、随机梯度下降(快但有噪声)和小批量梯度下降(平衡速度与准确性)。该算法解决了大规模模型训练问题,但需权衡局部最优风险与超参数调优难度。核心公式θ=θ-η×∇L(θ)体现了"沿最陡下坡方向迈步&quo

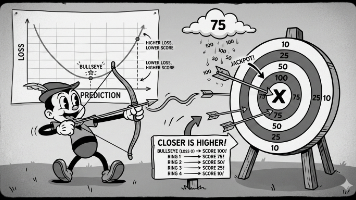
摘要: 损失函数是机器学习的核心概念,用于量化模型预测与真实值的差距。它解决了模型优化的方向性问题,通过数学公式(如均方误差MSE和交叉熵)自动计算误差,使模型能够通过梯度下降等优化方法自动调整参数。损失函数的设计需考虑任务特性,不同任务需要选择不同函数(回归用MSE,分类用交叉熵)。其本质是模型的"成绩单",通过最小化损失值指导模型学习。虽然通用损失函数可能不完全契合具体任务
自监督学习是AI领域的重要范式,通过设计预任务从无标签数据中学习有效表示。核心思想是利用数据自身结构创造监督信号,主要有两种方法:对比学习(拉近正样本、推远负样本)和掩码重建(预测被遮部分)。这种方法解决了标签依赖问题,但可能牺牲任务相关性并增加预训练成本。典型应用包括BERT和MAE等模型,本质是让模型"自己给自己出题"进行学习。
