




- @fyfugoyfa
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Claude Code 太贵?这五个工具都能让 Claude Code 支持更多自定义模型 + API 中转!

一文学会大语言模型权重文件哈希校验 Python 脚本
一文理解在 VSCode 中成功使用 Claude Code 插件
OpenCode 是当前 AI 编程工具领域最活跃的开源项目之一。截至 2026 年 2 月,该项目在 GitHub 上已获得 99.3k 星标,月活跃开发者超过 250 万,支持 75 种以上大语言模型提供商。OpenCode 的核心价值在于打破供应商锁定:代码基于 MIT 许可证完全开源,架构支持本地模型部署以保障隐私,并独创 Plan/Build 双模式工作流,为开发者提供高度的灵活性与控制

EdgeClaw 于 2026 年 2 月 12 日正式发布,是一款端云协同个人 AI 助手,代表了 AI Agent 隐私保护领域的重要技术突破。该系统由清华大学自然语言处理实验室(THUNLP)、中国人民大学、AI9Stars、ModelBest(面壁智能)与 OpenBMB 联合开发,基于开源 AI Agent 框架 OpenClaw 构建。其核心创新在于提出了三层安全协议(S1/S2/S3

ClawXRouter 是一款开源的 AI 智能体路由插件。它的工作原理类似于医院的“分诊员”:自动判断每个请求该由本地模型处理,还是交给云端模型处理。它通过三个关键机制——敏感信息分级、脱敏回填、任务复杂度评估,在无需修改业务代码的前提下,同时兼顾隐私保护、安全性、成本控制和任务效果。实测数据显示,使用 ClawXRouter 可降低约 58% 的 API 调用成本,并提升约 6.3% 的任务执

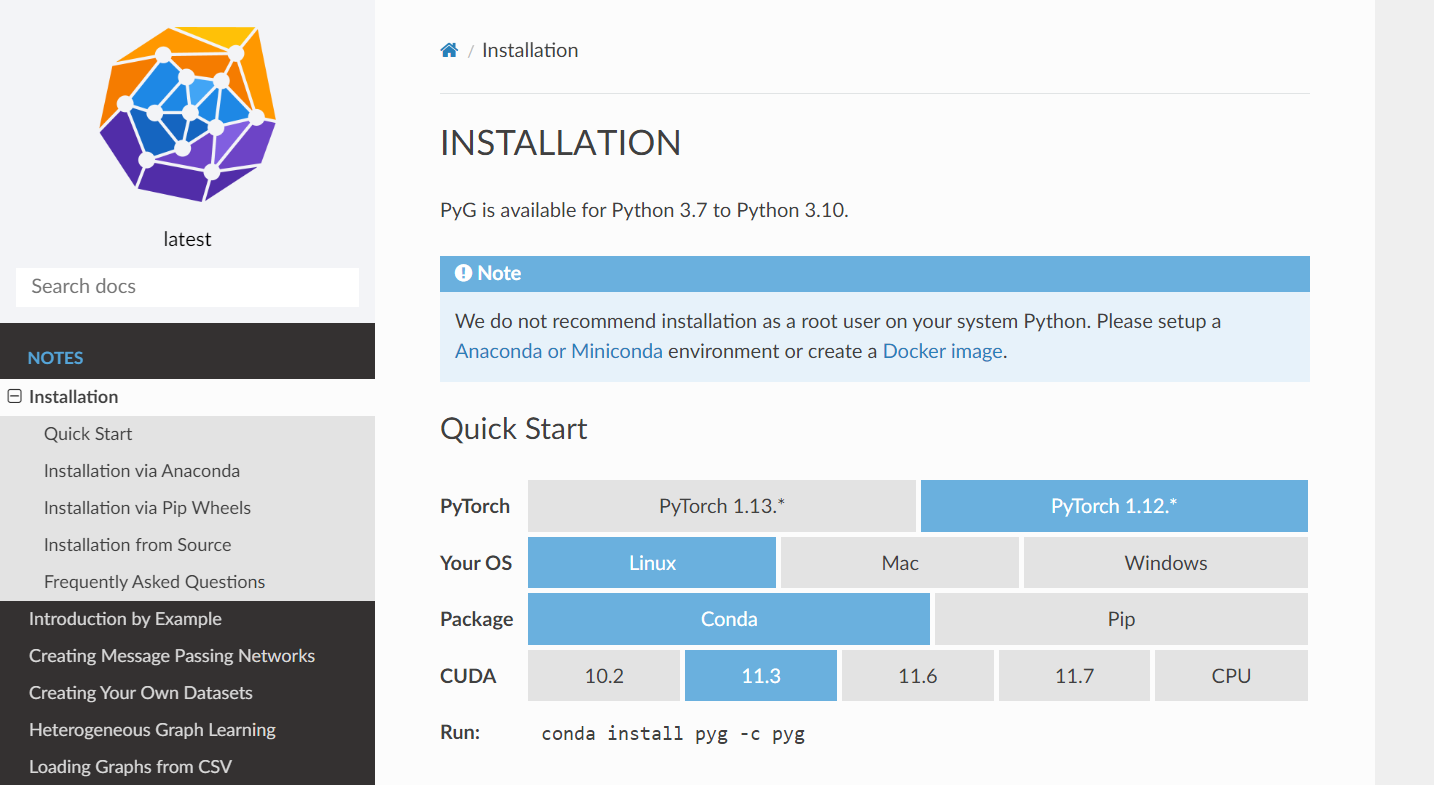
图机器学习 | PyG 安装配置记录
2023 年 “华为杯” 第二十届中国研究生数学建模竞赛一等奖 总结和复盘

TileLang 旨在简化高性能 GPU/CPU 内核(Kernels)的开发,例如 MLA(Multi-Head Latent Attention)、GEMM(GEneral Matrix Multiplication)、Dequant GEMM、FlashAttention 和 LinearAttention 等。通过在 TVM 之上构建底层编译器基础设施,并采用 Pythonic 语法,ti

一文理解机器学习中二分类任务的评价指标 AUPRC 和 AUROC
