- @fantasygwh2015
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
连续性与无限分辨率:因为它是一个数学函数,你可以无限放大图像/物体而不出现马赛克(锯齿)。就像矢量图一样,但它可以表示照片级的细节。存储效率:对于复杂的3D形状,存储神经网络的权重可能比存储巨大的体素网格(Voxel Grid)要小得多。可微性:整个表示是可微分的。这意味着你可以通过反向传播,直接利用2D图片来优化3D形状(这是 NeRF 成功的根本原因)。拓扑无关:它不需要像 Mesh 那样处理
deeplizard学习

deeplizard学习
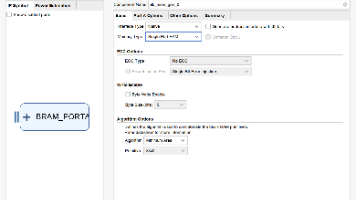
用于设置端口的复位信号,可以添加一个复位信号(RSTA Pin)、设置复位时ram 输出总线上的数据值(Output Reset Value )、设置是否复位内置锁存器(Reset Memory Latch)和设置复位信号与时钟使能之间的优先级(Reset Priority)。• No Change(不变模式):在该模式下,进行写操作时,读数据线上的数据保持不变。:读深度,当写数据位宽、读数据位宽
这强迫上游的 FIFO 必须将数据存入内部 RAM,从而验证 FIFO 的缓存功能和满标志逻辑是否正常工作。它定义了用于同步信号的寄存器级数,通常用于防止亚稳态。设为 No,意味着这个 FIFO 认为数据是无限连续的流,没有“包”的概念。如果是同步 FIFO,这两个值通常是一样的。,TKEEP (Keep) 用于指示数据流中的哪些字节是有效的(通常用于处理非对齐的数据包尾部)。它是一个紧急警告信号
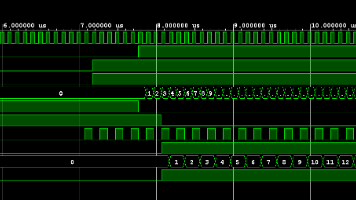
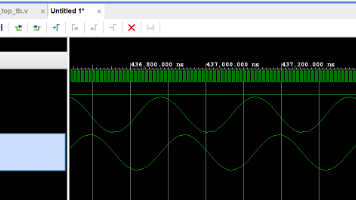
最终输出的结果,就是读取coe文件中的波形,即sin函数。当然可以用matlab生成各种各样的波形来进行读取。本实验主要读取rom中的数据。rom中存储的数据为coe文件,用matlab可以生成。本仿真采用ROM核,位数11位,深度512.
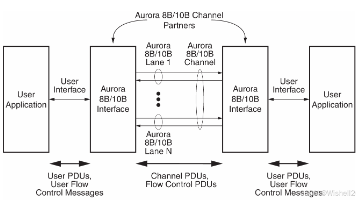
代码组是8B / 10B编码字节对,所有数据都作为代码对发送,因此具有奇数个字节的用户帧具有称为PAD的控制字符,附加到帧的末尾以填写最终的代码组。也就是说,使用的GT高速收发器的通道越多、且其支持的线速率越高,则整个Aurora 8B/10B IP核的吞吐率越高,但是要注意乘以80%,因为8B/10B编码存在20%的开销。这些数据用户是看不见的,属于协议层的开销。,这很重要,因为 Aurora
采用DDS的IP核,具体IP核设置见ip核的解析。
Aurora 8B/10B 协议是一种可扩展的轻量级链路层协议,可用于在一条或多条高速串行通道上进行点对点数据传输。该协议本身独立于上层协议,既能承载以太网、TCP/IP 等标准协议,也能承载专有协议,从而让下一代通信与计算系统的设计者在保留现有软件投入的同时,获得更高的互连性能。虽然主要面向芯片间和板间应用,但只要增加标准的光接口组件,Aurora 8B/10B 协议也可用于机箱间的互连。Aur
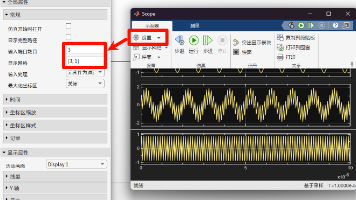
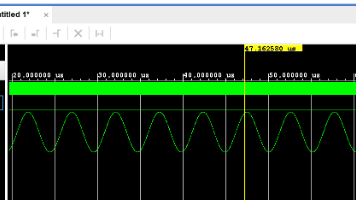
在vivado中仿真了濾波器,現在看看怎么用simulink进行仿真,算是一种互相的印证与学习。