- @dgvv4
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大家好,今天和各位分享一下 Transformer 中的 Encoder 部分涉及到的知识点:Word Embedding、Position Embedding、self_attention_Mask本篇博文是对上一篇 《Transformer代码复现》的解析,强烈建议大家先看一下:https://blog.csdn.net/dgvv4/article/details/125491693由于 Tr
Deepmind 提出的 SAC (Soft Actor Critic) 算法是一种基于最大熵的无模型的深度强化学习算法,适合于真实世界的机器人学习技能。SAC 算法的效率非常高,它解决了离散动作空间和连续性动作空间的强化学习问题。SAC 算法在以最大化未来累积奖励的基础上引入了最大熵的概念,加入熵的目的是增强鲁棒性和智能体的探索能力。SAC 算法的目的是使未来累积奖励值和熵最大化,使得策略尽可能
Deepmind 提出的 SAC (Soft Actor Critic) 算法是一种基于最大熵的无模型的深度强化学习算法,适合于真实世界的机器人学习技能。SAC 算法的效率非常高,它解决了离散动作空间和连续性动作空间的强化学习问题。SAC 算法在以最大化未来累积奖励的基础上引入了最大熵的概念,加入熵的目的是增强鲁棒性和智能体的探索能力。SAC 算法的目的是使未来累积奖励值和熵最大化,使得策略尽可能
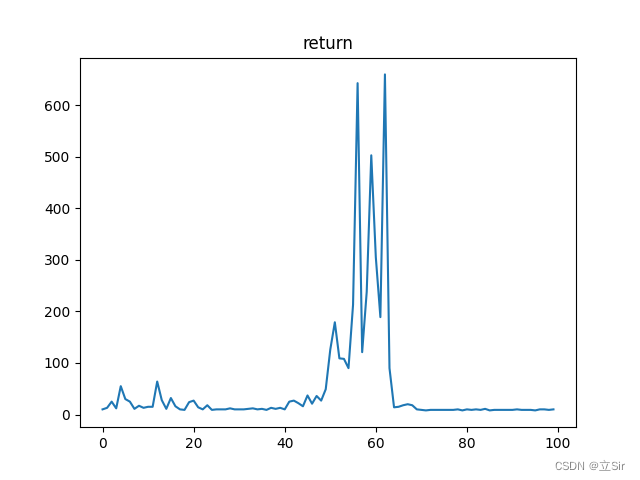
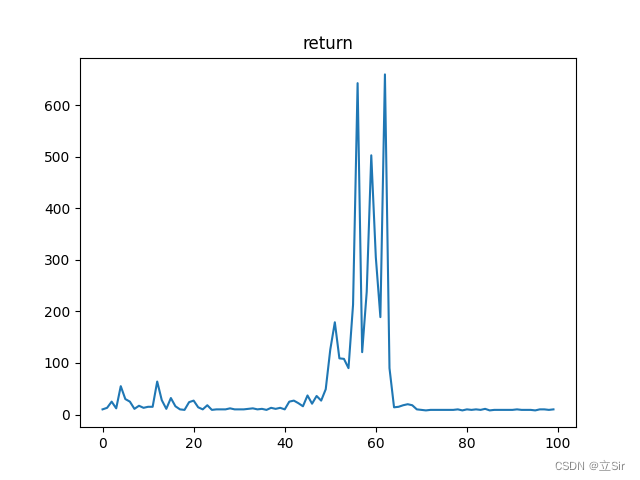
Deepmind 提出的 SAC (Soft Actor Critic) 算法是一种基于最大熵的无模型的深度强化学习算法,适合于真实世界的机器人学习技能。SAC 算法的效率非常高,它解决了离散动作空间和连续性动作空间的强化学习问题。SAC 算法在以最大化未来累积奖励的基础上引入了最大熵的概念,加入熵的目的是增强鲁棒性和智能体的探索能力。SAC 算法的目的是使未来累积奖励值和熵最大化,使得策略尽可能
Deepmind 提出的 SAC (Soft Actor Critic) 算法是一种基于最大熵的无模型的深度强化学习算法,适合于真实世界的机器人学习技能。SAC 算法的效率非常高,它解决了离散动作空间和连续性动作空间的强化学习问题。SAC 算法在以最大化未来累积奖励的基础上引入了最大熵的概念,加入熵的目的是增强鲁棒性和智能体的探索能力。SAC 算法的目的是使未来累积奖励值和熵最大化,使得策略尽可能
Deepmind 提出的 SAC (Soft Actor Critic) 算法是一种基于最大熵的无模型的深度强化学习算法,适合于真实世界的机器人学习技能。SAC 算法的效率非常高,它解决了离散动作空间和连续性动作空间的强化学习问题。SAC 算法在以最大化未来累积奖励的基础上引入了最大熵的概念,加入熵的目的是增强鲁棒性和智能体的探索能力。SAC 算法的目的是使未来累积奖励值和熵最大化,使得策略尽可能