




- @cc_beolus
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如280 TFLOPS FP16算力,指的是每秒280 *(10^12)次半精度浮点运算;560 TOPS INT8算力,指的是每秒560 *(10^12)次整型运算。1MFLOPS: 等于每秒一百万(=10^6)次浮点运算;1GFLOPS: 等于每秒十亿(=10^9)次浮点运算;1TFLOPS: 等于每秒一万亿(=10^12)次浮点运算;1PFLOPS: 等于每秒一千万亿(=10^15)次浮点运

如280 TFLOPS FP16算力,指的是每秒280 *(10^12)次半精度浮点运算;560 TOPS INT8算力,指的是每秒560 *(10^12)次整型运算。1MFLOPS: 等于每秒一百万(=10^6)次浮点运算;1GFLOPS: 等于每秒十亿(=10^9)次浮点运算;1TFLOPS: 等于每秒一万亿(=10^12)次浮点运算;1PFLOPS: 等于每秒一千万亿(=10^15)次浮点运
如280 TFLOPS FP16算力,指的是每秒280 *(10^12)次半精度浮点运算;560 TOPS INT8算力,指的是每秒560 *(10^12)次整型运算。1MFLOPS: 等于每秒一百万(=10^6)次浮点运算;1GFLOPS: 等于每秒十亿(=10^9)次浮点运算;1TFLOPS: 等于每秒一万亿(=10^12)次浮点运算;1PFLOPS: 等于每秒一千万亿(=10^15)次浮点运
1.可以尝试调整prefill阶段的批次;2.可以调整调度策略;3.可以调整客户端的请求并发量和请求频率;由于是基于上面优化基础上,叠加优化,所以要和上面最好的一次性能做比较,即2655.测试性能比默认还要差?分析可能是客户端并发设置太小了(当前设置100)数据解析后生成的内容:(在命令执行路径下的output目录)
深入浅出完整解析Stable Diffusion(SD)核心基础知识深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识。
牵引快速把在GPU训推的pytorch模型迁移到昇腾硬件上,使用cann,torch_npu, mindie等关键组件

AIPP(Artificial Intelligence Pre-Processing)人工智能预处理,用于在 AI Core 上完成数据预处理,包括改变图像尺寸、色域转换(转换图像格式)、减均值 / 乘系数(改变图像像素),数据预处理之后再进行真正的模型推理。性能调优流程:性能数据采集-》算子层优化-》调度策略调整-》通信机制-》模型编译下发等。:量化可以模型压缩、减少计算量、缩短推理时延,但可
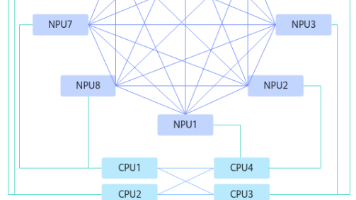
通过HCCS实现两两互联(Full Mesh),如NPU与NPU之间,CPU与CPU之间;NPU和CPU之间通过PCIE连接。Full Mesh是指在一个网络拓扑中,每个节点都直接连接到其他节点,形成一个完全互联的网络结构。在Full Mesh网络中,任何两个节点之间都可以直接通信。双mesh组网(8P Full-mesh)
一般用户是根据自己的业务场景,比如说要跑DeepSeek满血版推理,则需要去看对应的镜像哪个版本满足要求,然后再根据镜像安装的CANN版本去看宿主机的固件驱动版本是否满足,如果不满足需要升级驱动固件。开发者拿到一个裸机环境,如800I A2/800T A2, 或Atlas 800 3000推理服务器(里面插了Iduo卡),需要用户根据OS版本去安装配套的固件驱动、Mind系列软件等。一般建议选择新
离线推理(om模型在昇腾acl推理)的结果和在线推理(如:对原始模型通过pytorch/onnxruntime框架在gpu/cpu的推理)相差比较大,如在开源数据集的精度差距>1%,则认为离线推理精度不达标。这里是以在线推理的结果作为基准参考。