
写文章




- @Stella_Conch
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeek_R1技术报告 超细致中文详解
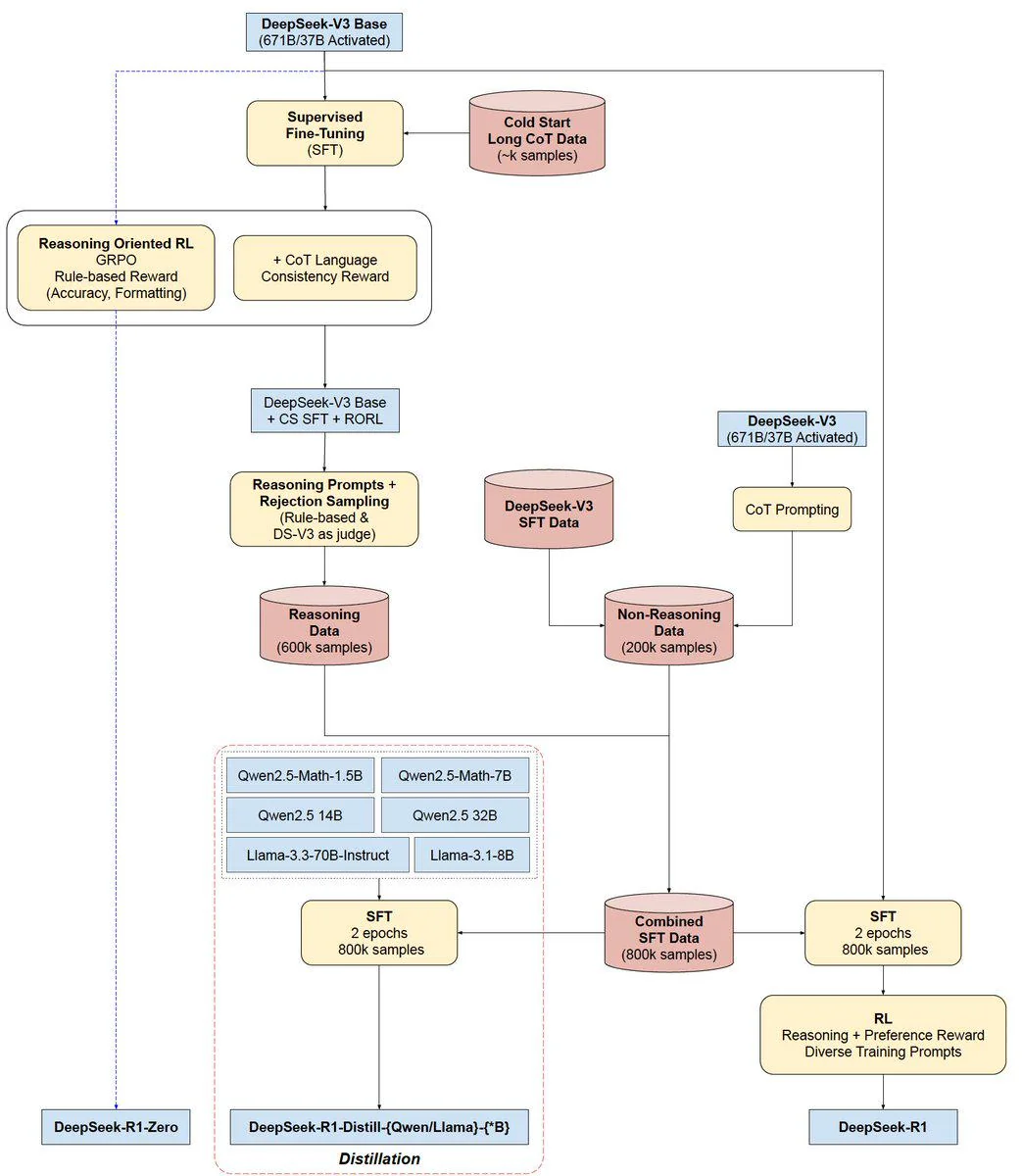
仅使用强化学习(RL)激励推理能力,而不使用有监督的人工微调(SFT)→ 推理强,但存在可读性差、语言混淆的问题。则在RL之前加入了**多阶段训练(RL + 拒绝采样 + SFT)**和少量的冷启动数据最终效果可以达到OpenAI-o1-1217的推理效果。、基于Qwen2.5和Llama3从DeepSeek_R1 蒸馏 distillation出来的六个密度的模型**(1.5B, 7B, 8B,
SWiRL (Step-Wise Reinforcement Learning)论文笔记
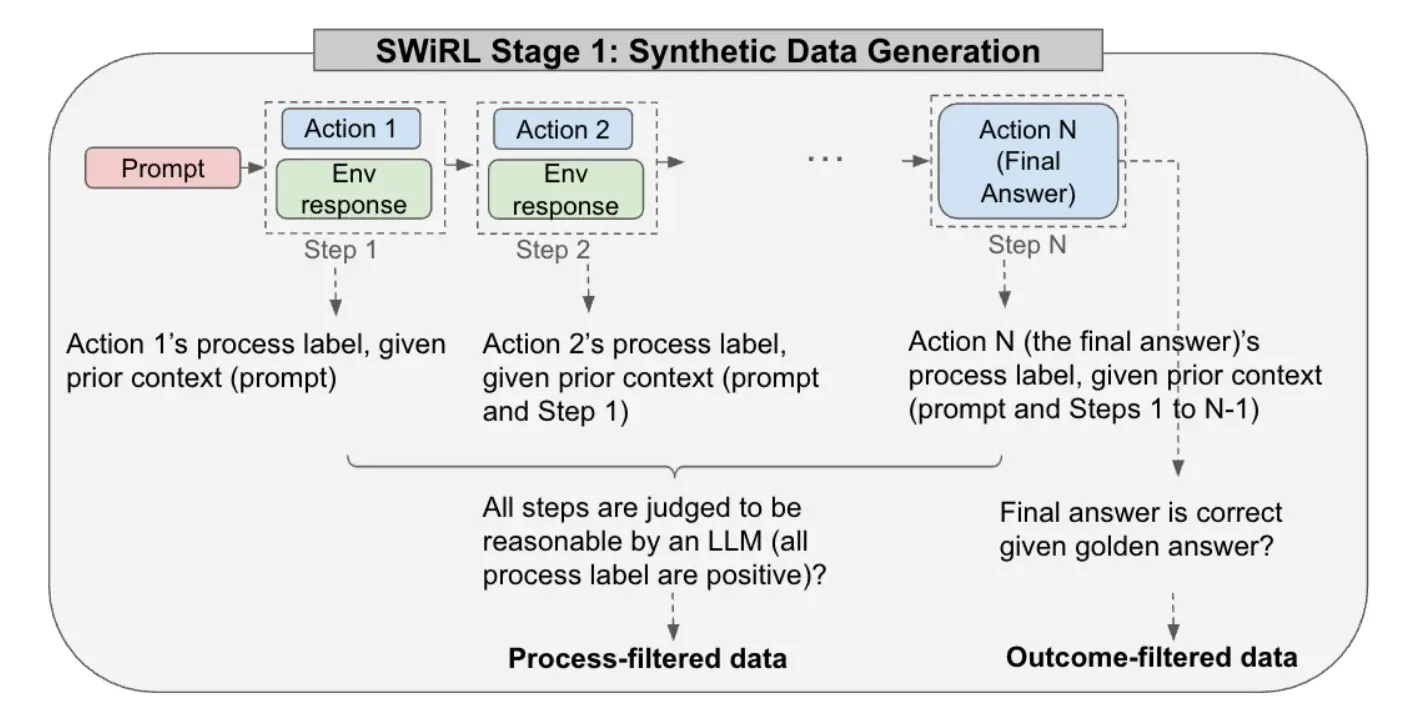
Step-Wise Reinforcement Learning (SWiRL)——一种离线多步优化技术通过合成数据生成和多步强化学习提升语言模型在复杂推理和工具使用任务中的能力离线训练:通过合成数据实现高效、可重复的优化,避免在线工具调用带来的延迟。多步轨迹生成:通过LLM(如开源Gemma 2)与工具(如搜索引擎/计算器)交互,自动生成多步推理轨迹 trajectory(包含中间步骤的工具调用
DeepSeek_R1技术报告 超细致中文详解
仅使用强化学习(RL)激励推理能力,而不使用有监督的人工微调(SFT)→ 推理强,但存在可读性差、语言混淆的问题。则在RL之前加入了**多阶段训练(RL + 拒绝采样 + SFT)**和少量的冷启动数据最终效果可以达到OpenAI-o1-1217的推理效果。、基于Qwen2.5和Llama3从DeepSeek_R1 蒸馏 distillation出来的六个密度的模型**(1.5B, 7B, 8B,
到底了