
写文章




- @Mjl200412
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
L1正则化 vs L2正则化
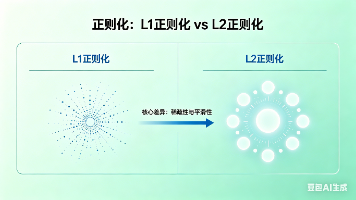
本文系统介绍了机器学习中的正则化技术。首先区分了欠拟合和过拟合的表现:欠拟合是模型过于简单导致训练集和测试集表现均差;过拟合则是模型过于复杂,记住了训练数据噪声导致泛化能力下降。针对这两种情况,文章分别给出了解决方案。 重点阐述了L1和L2正则化的区别:L1会产生稀疏权重,适用于特征选择和模型压缩;L2产生平滑权重,更适合防止过拟合。文章提供了三种选择策略:(1)优先使用L2提升泛化能力;(2)需
到底了