




- @JellyAI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这是一系列文章的第一篇,教你如何提升神经网络训练过程中的监控和排查能力:1.更好的方式来监控神经网络训练(本篇)2.神经元死亡问题(即将推出)3.梯度消失与爆炸(即将推出)4.小心梯度震荡(即将推出)

如今,人工智能已经成为几乎所有企业执行工作的关键角色,各大公司纷纷投入研发和维护AI工具,以充分发挥AI的优势,从而推动业务增长,也就是创造更多收入。如果你正苦恼于该从何处入手,想要寻找一些既能为你的作品集增色,又不会像“计算器AI”那样简单的项目,那么请继续往下看,我已经帮你准备好了!另一方面,由于公司希望在团队中招聘AI专家,他们寻找的并不仅仅是会使用AI的人,而是能够根据公司的需求,量身定制

因为它的激励实在是太大了——想象一下,强大的 AI 系统只需极低的能耗,这意味着它们可以脱离数据中心,实现 移动化,就像人类一样自由行动。然而,这些模拟给出的答案有时是正确的,有时是错误的,就像真实的神经网络会做的那样,就像大脑会做的那样。此外,它们的能耗要低得多——事实上,它们使用的是化学能,而不是电能。但你只需要知道的是,像图中这样的“神经元”是 AI 系统的基本构造块,就像神经元是大脑的构造
国际贸易管理局对跨境电商的定义很直白,简单来说,跨境电商就是通过互联网(这里的互联网可以是商家自己的网站或者电商平台上的店铺)把本国的商品卖给国外的消费者,然后通过国际物流把商品送到他们手中。很多时候,一个国家的市场可能会被某些类型的商品占满,多个公司在有限的市场中争夺更大的份额。此外,国际贸易让企业接触到使用不同方法和策略的外国竞争对手,这能够让企业从中学习,获得更深刻的见解,并激发创新。来自不
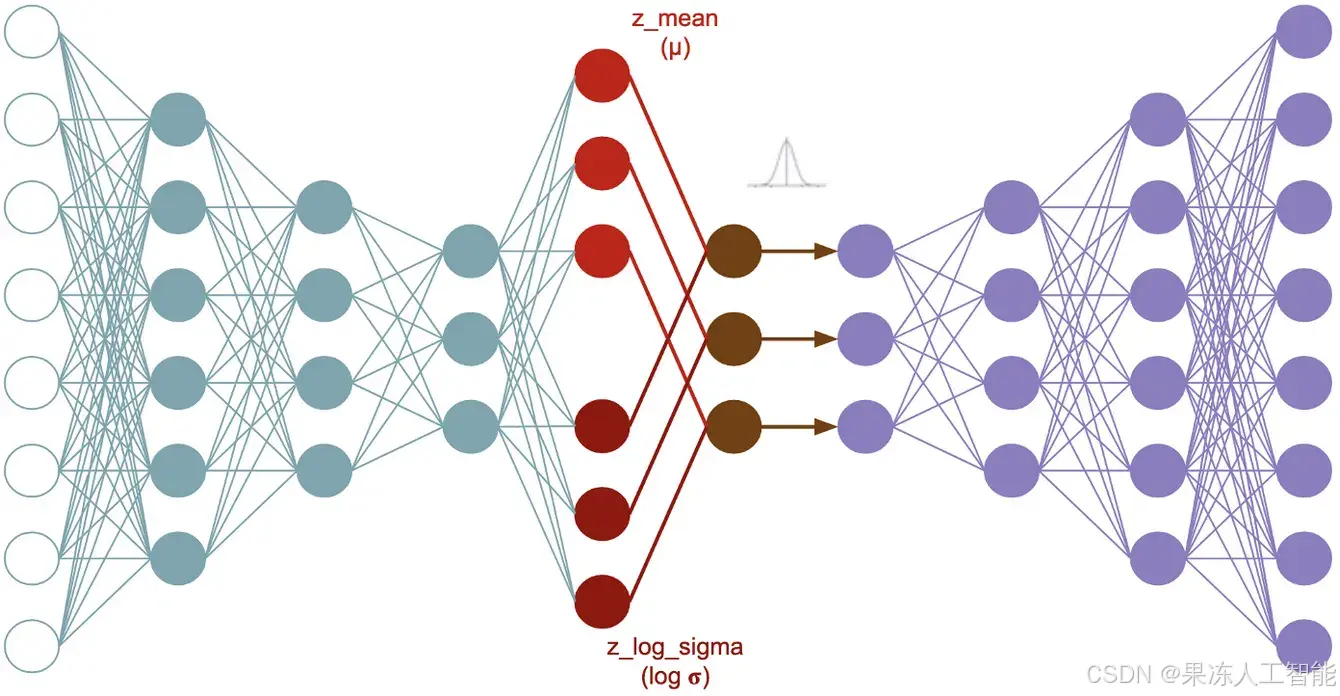
验证数据在训练过程中用于查看网络在之前未见过的数据上的表现——即,它并不是用来拟合数据和标签的,而是用来检查拟合的效果如何。其次,这些图像是全彩色的,而不是灰度的,因此每张图像将拥有三个通道而非一个。记住,这是因为我们的输入图像是 300 × 300 的彩色图像,所以有三个通道,而不是之前用于单色 Fashion MNIST 数据集的一个通道。刚开始我的 AI 之旅时,一个让我感到非常沮丧的问题是

随着时间的推移,我们希望将这个值与期望的输出匹配——在这个图像中,我们可以看到期望的输出是数字9,也就是图2-3中展示的短靴的标签。虽然这样可以工作,但我们可能希望训练直到达到期望的准确率,而不是反复尝试不同的周期数,进行训练和重新训练,直到得到我们想要的值。本文介绍的计算机视觉,简单来说,是让计算机通过算法从图像中提取特征,并使用这些特征来表示图像中的各种元素及它们的相互关系,从而实现“看”的效

FLUX.1 (2024):Black Forest Lab 推出了FLUX.1,这是一个先进的扩散模型,用于AI图像生成,具有出色的速度、质量和对提示的响应能力。1969年,XOR问题暴露了感知器(单层神经网络)的局限性。•GPT (2018):生成式预训练Transformer(Generative Pre-trained Transformer),由OpenAI提出,是一个自回归的、仅使用解

Sora的仪表盘设计简洁直观,支持管理项目、按提示或风格筛选内容,并将文件归类到文件夹中。Sora的故事板功能尤为突出,它允许用户通过时间轴组合多个提示,制作连贯的叙事视频。例如,用户可以创作一个男人站在悬崖上并在满月下变成狼的动画,展现帧与帧之间的流畅过渡。如果你是一名内容创作者、营销人员,或者只是对AI在视频制作中的潜力感到好奇,那么Sora值得一试。Sora在竞争激烈的AI视频生成领域中脱颖
研究表明,人们更愿意相信一个头发花白、拥有博士学位的专家,而不是一个匿名的信息源,即使两者讲述的内容完全相同。• Goel等人:在一项涉及 1690 名美国参与者的实验中,研究人员探讨了人们是否更信任AI生成的信息,而非人类来源的信息。因为信任不仅仅是一个理性过程,它是情感化的、社交性的、文化嵌入式的。最近的两项研究——一项由Costello、Pennycook和Rand发表在《Science》期

OpenAI最初公开了ChatGPT-2的语言模型(LLM)源代码,但在随后的ChatGPT-3及之后的版本中停止了开源,逐渐背离了最初的开放承诺,导致公司内部核心成员的相继离开。唯一的区别是,除了将已生成的单词输入解码器外,还将编码器输出的德语句子作为额外输入。标准差是一个统计量,用于描述数值的分布范围(在一组数字中),例如,如果所有值都相同,则标准差为零。基本上,你在将一个块层层堆叠,前一个块
