




- @Jason_Sun_2009
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 本文介绍了一种本地部署AI智能体的方案,采用Ollama作为模型后端+Hermes作为运行框架的组合。文章分析了该方案的硬件适配性——Intel Mac性能局限导致小模型(如0.5B参数的Qwen)速度尚可(102.6 tokens/s)但能力不足,而实用级大模型(如DeepSeek-R1)速度骤降至6.2 tokens/s。重点推荐Hermes的核心优势:分层记忆管理、全会话持久化、终端
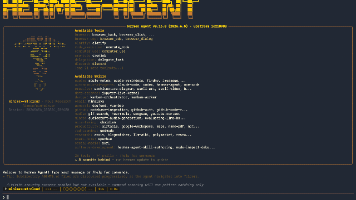
摘要: 本文介绍了一种本地部署AI智能体的方案,采用Ollama作为模型后端+Hermes作为运行框架的组合。文章分析了该方案的硬件适配性——Intel Mac性能局限导致小模型(如0.5B参数的Qwen)速度尚可(102.6 tokens/s)但能力不足,而实用级大模型(如DeepSeek-R1)速度骤降至6.2 tokens/s。重点推荐Hermes的核心优势:分层记忆管理、全会话持久化、终端
摘要: 本文介绍了一种本地部署AI智能体的方案,采用Ollama作为模型后端+Hermes作为运行框架的组合。文章分析了该方案的硬件适配性——Intel Mac性能局限导致小模型(如0.5B参数的Qwen)速度尚可(102.6 tokens/s)但能力不足,而实用级大模型(如DeepSeek-R1)速度骤降至6.2 tokens/s。重点推荐Hermes的核心优势:分层记忆管理、全会话持久化、终端
摘要: 本文介绍了一种本地部署AI智能体的方案,采用Ollama作为模型后端+Hermes作为运行框架的组合。文章分析了该方案的硬件适配性——Intel Mac性能局限导致小模型(如0.5B参数的Qwen)速度尚可(102.6 tokens/s)但能力不足,而实用级大模型(如DeepSeek-R1)速度骤降至6.2 tokens/s。重点推荐Hermes的核心优势:分层记忆管理、全会话持久化、终端