




- @Fire_to_cheat_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们将看到调度器如何像一个睿智的指挥官,统筹安排每个请求的处理时机,以及内存管理器如何通过创新的 PagedAttention 机制,让有限的显存发挥出最大效能。调度器会判断是否有足够的内存块可以分配给新的 tokens。在模型部署的初始化阶段,vLLM 会通过一个模拟实验步骤来决定 GPU 和 CPU 上可以分配的 KV cache 物理块数量,确保后续推理时的内存分配不会导致显存溢出。从最初的

一、TensorFlow 简介TensorFlow 是 Google 开源的一款人工智能学习系统。为什么叫这个名字呢?Tensor 的意思是张量,代表 N 维数组;Flow 的意思是流,代表基于数据流图的计算。把 N 维数字从流图的一端流动到另一端的过程,就是人工智能神经网络进行分析和处理的过程。话说在 Android 占领了移动端后,Google开源了 TensorFlow,希望
一、TensorFlow 简介TensorFlow 是 Google 开源的一款人工智能学习系统。为什么叫这个名字呢?Tensor 的意思是张量,代表 N 维数组;Flow 的意思是流,代表基于数据流图的计算。把 N 维数字从流图的一端流动到另一端的过程,就是人工智能神经网络进行分析和处理的过程。话说在 Android 占领了移动端后,Google开源了 TensorFlow,希望
我们将看到调度器如何像一个睿智的指挥官,统筹安排每个请求的处理时机,以及内存管理器如何通过创新的 PagedAttention 机制,让有限的显存发挥出最大效能。调度器会判断是否有足够的内存块可以分配给新的 tokens。在模型部署的初始化阶段,vLLM 会通过一个模拟实验步骤来决定 GPU 和 CPU 上可以分配的 KV cache 物理块数量,确保后续推理时的内存分配不会导致显存溢出。从最初的
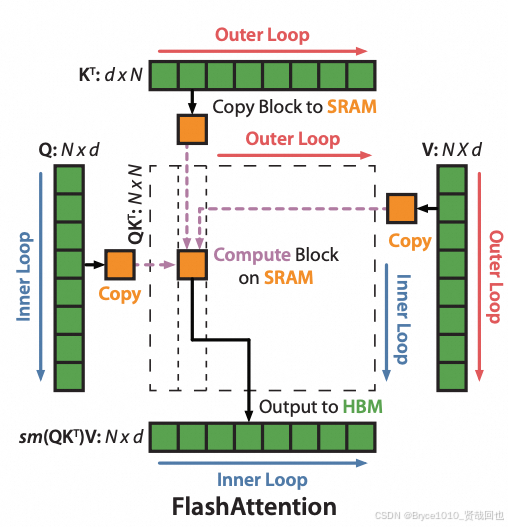
FlashAttention 原理之 softmax 分块计算
如果对网络层每一层都要重新实现LoRA的方法,是比较复杂的,推荐使用HuggingFace的封装库peft,覆盖基本的网络模型。共用基础LLM是未来的趋势,如果需要快速适应特殊的任务,只需要训练LoRA的参数即可,大大降低了GPU的使用量;当不同任务的切换时,只需要切换不同的LoRA参数;

我们将看到调度器如何像一个睿智的指挥官,统筹安排每个请求的处理时机,以及内存管理器如何通过创新的 PagedAttention 机制,让有限的显存发挥出最大效能。调度器会判断是否有足够的内存块可以分配给新的 tokens。在模型部署的初始化阶段,vLLM 会通过一个模拟实验步骤来决定 GPU 和 CPU 上可以分配的 KV cache 物理块数量,确保后续推理时的内存分配不会导致显存溢出。从最初的
周志华机器学习BP改进试设计一个算法,能通过动态调整学习率显著提升收敛速度,编程实现该算法,并选择两个UCI数据集与标准的BP算法进行实验比较。1.方法设计传统的BP算法改进主要有两类:- 启发式算法:如附加动量法,自适应算法- 数值优化法:如共轭梯度法、牛顿迭代法、Levenberg-Marquardt算法(1)附加动量项这是一种广泛用于加速梯度下降法收敛...
vLLM 的调度系统是一个精心设计的多层次架构,通过多个协同工作的组件实现了高效的资源管理和任务调度。让我们从整体到细节来回顾这个系统。

一、逻辑逻辑是一种可以从中找出结论的形式化语言。句法(规则)用语言定义句子。语义定义句子的含义。定义一个句子的真假性。二、蕴含即一个事情逻辑上是另一个事情的必然结果:KB ╞ α知识库KB蕴含句子α,当且仅当α在所有KB为真的世界里均为真。蕴含是基于语法的句子关系。三、命题逻辑命题逻辑是