




- @Botaruibo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
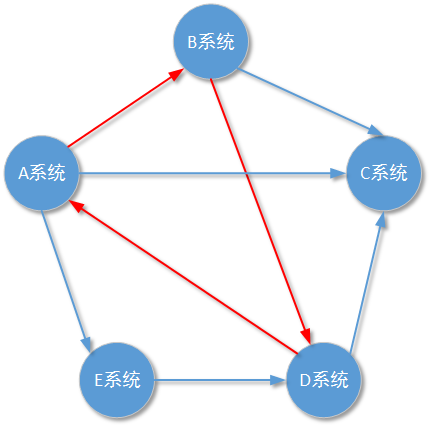
一、循环依赖有哪些首先我们要讲清楚什么是循环依赖,以及循环依赖的在程序设计层面、软件产品设计层面、顶层架构设计层面上可能出现的场景。从概念模型上讲,只要两个或多个元素产生相互依赖关系,就可以看成产生了循环依赖:上图是两个依赖关系正确的示例:A元素正常工作依赖于B元素的正常工作,或者A元素的正常工作依赖于B、C、D元素的正常工作。这里的A、B、C、D四个元素可以指代四段代码,也可以指代一个业务系统中
先引用IDMer整理的图初步了解下K-meansK-means也被称为C-means,因为它的目标是要找到c个均值向量u1,u2,……uc。除上面提到的用处,k-means还常用于加速其它算法的收敛。聚类算法主要有两类:硬聚类和软聚类(FCM)。K-means属于前者。K-means的两大难点是确定c的数值和避免算法的抖动(不稳定性)。对这两个问题都有大量的针对性的
先引用IDMer整理的图初步了解下C4.5C4.5的优缺点在上图中已经列出。C4.5是一种基于ID3的决策树分类算法,通常归类为统计分类器。先介绍下决策树决策树分类的步骤是:所有待决策的样本都位于树根,参数都为离散化取值。根据启发规则选择一个参数,根据该参数取值的不同对样本进行划分。对划分后的每个部分重复1,2步。直到划分在一起的样本属于同一类或者参数耗尽(
http://tnove.com先引用IDMer整理的图初步了解下Apriori 上面对apriori算已经做了简单介绍。该算法最早用于购物篮挖掘,频繁项的挖掘。其伪代码为:Apriori算法的缺点在于其在实际计算中消耗较大,针对Apriori的缺点华裔学者韩家炜提出FP-Tree算法针对Apriori存储扫描进行了改进。同时FP-tree为TOP 10
SVM(support vector machine)是一种基于分类间隔(margin)来训练的分类器,它是在1995年左右由Vapnik等人基于VC维而提出的高效分类器,其原理如下图最大化类间间隙。参考出处 SVM主要用于解决小样本和非线性分类问题。SVM解决非线性问题的办法为通过将原有的非线性可分的空间通过映射转换到高维线性可划分空间中,因此SVM会使得特征空间的维数升高。此
http://www.tnove.com/?p=209 一直想对top 10 algorithms in data mining 中的算法做一些分析介绍,也作为自己的一个回顾。但一直都没有时间来做,现在终于抽出一些时间来写点东西。 首先对该事件做一个介绍。事件发生于The 2006 IEEE International Conference on Data Minin
Adaboost 是boosting算法的变形,全称为adaptive boosting(自适应增强)。该方法主要是通过多个弱分类器的集合来使得分类误差达到足够小。理论上通过adaboost方法可以使得分类误差为0。但我们知道通常情况下训练分类器误差为0时会过拟合。 关于boosting算法参考《Boosting Foundations and Algorithms》以及wik
Pagerank因google的快熟发展并提供高质量搜索结果而受到广泛关注。Pagerank的主要目标是评价网页的重要程度,并以此作为网页的排名依据。算法主要参考网页被引用的数量,及引用者的权威性。参考下面的简单的网页引用模型: 首先我们需要一个合适的数据结构来表示这个网络结构。这涉及到图的表示,我们在数据结构课程中学过,常用的方法是邻接矩阵法和链接法。实际中不会单独的只使用某一种
EM的核心是通过已有的数据来递归的估计似然函数,常用用在样本特征丢失的情况中。其前身为Baum-Welch算法。EM与K-means比较:计算复杂,收敛较慢,依赖初始值,容易进入局部最优点。 K-means的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特
强制关闭tomcat进程,并拷贝包并重新启动tomcat:export JAVA_HOME=/yougo/javaecho ‘尝试关闭tomcat…’sh bin/shutdown.sh;tom_pid=ps -ef|grep group-new|grep -v grep| awk '{print $2}'#如果tom_pid长度不为零not-zero