- @Angelina_Jolie
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
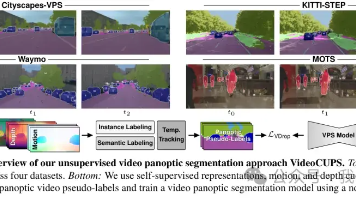
慕尼黑工业大学等机构联合推出VideoCUPS,首次实现无需人工标注的无监督视频全景分割(VPS)。该方法仅需单目视频,通过运动线索和深度信息自动生成高质量伪标签,并引入VideoDropLoss和自增强训练策略提升性能。实验表明,VideoCUPS在Cityscapes-VPS等数据集上STQ指标达22.2%,跨域泛化能力强,且仅需10%标注数据微调即可达到全监督效果。这一突破大幅降低了VPS的
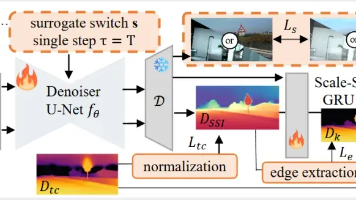
本文提出Jasmine,首个基于Stable Diffusion的自监督单目深度估计框架。通过混合批次图像重建(MIR)代理任务保护SD视觉先验,无需高精度监督;设计Scale-Shift GRU(SSG)模块解决尺度分布不对齐问题。在KITTI基准上达到自监督方法SoTA性能(AbsRel 0.090),并展现卓越的零样本泛化能力。实验表明,Jasmine在多个数据集上优于现有方法,同时保持丰富
摘要:多伦多大学团队提出REALM框架,通过将事件相机数据映射到RGB基础模型的共享潜空间,实现跨模态感知。该方法仅训练10%参数,使冻结的MASt3R模型能零样本处理事件数据,在特征匹配任务上AUC@5°提升至26.2%,部分场景性能提升9倍。REALM采用LoRA适配器和渐进式空间掩码训练策略,既保留RGB模型的几何语义先验,又解决事件数据稀疏性问题。实验表明其在宽基线匹配、深度估计等任务上超
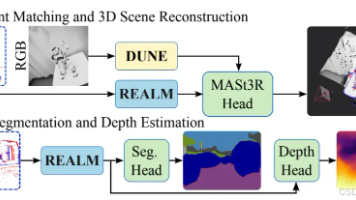
摘要:多伦多大学团队提出REALM框架,通过将事件相机数据映射到RGB基础模型的共享潜空间,实现跨模态感知。该方法仅训练10%参数,使冻结的MASt3R模型能零样本处理事件数据,在特征匹配任务上AUC@5°提升至26.2%,部分场景性能提升9倍。REALM采用LoRA适配器和渐进式空间掩码训练策略,既保留RGB模型的几何语义先验,又解决事件数据稀疏性问题。实验表明其在宽基线匹配、深度估计等任务上超
t-SNE的目标是帮助我们在一个更低维度的空间中(通常是2D或3D)对数据进行可视化,同时保留数据点之间的相似性关系。t-SNE的目标是最小化这两个概率分布之间的差异,以确保高维空间中相似的点在低维空间中仍然保持相似。然后,在低维空间中,它再计算点与点之间的相似性,并构建另一个概率分布。t-SNE的核心思想是保持高维空间中数据点之间的相似性关系,尽量在低维空间中保持相似的关系。简而言之,t-SNE

地址:https://cbovar.github.io/ConvNetDraw/

摘要: 浙江大学团队提出InfiniDepth,首次将神经隐式场引入单目深度估计,实现任意分辨率连续深度预测。通过多尺度局部隐式解码器(15M参数)和DINOv3 ViT-Large特征金字塔,该方法在合成数据集Synth4K上高频细节区域超越DepthAnythingV2等SOTA模型5-8个百分点。创新性InfiniteDepthQuery策略自适应分配子像素查询预算,显著改善大视角下的新视角
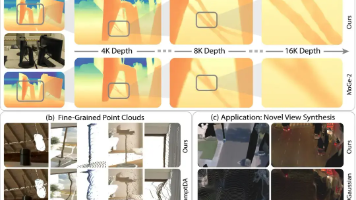
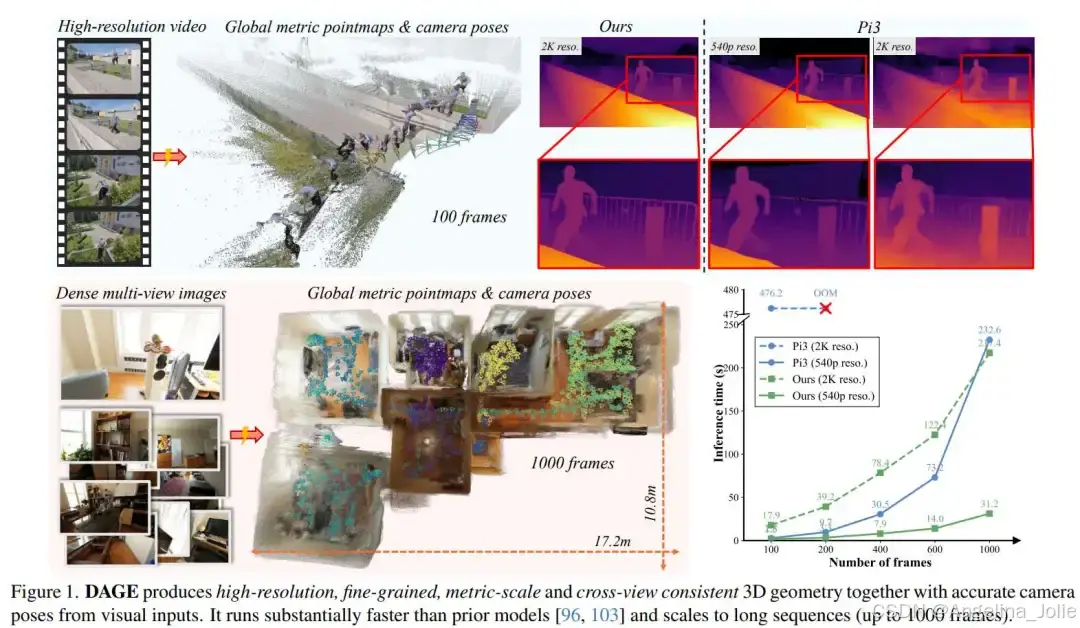
摘要: 本文提出DAGE,一种双流Transformer架构,用于高效、精细的几何估计。该模型通过低分辨率流处理全局一致性与相机姿态估计,采用交替注意力机制降低计算成本;高分辨率流则保留原始分辨率细节。轻量级适配器融合双流特征,实现全局一致且细节丰富的几何输出。实验表明,DAGE在3D重建、深度估计和相机姿态预测任务中达到SOTA性能,支持2K分辨率和长序列处理(最高1000帧),运行速度显著优于
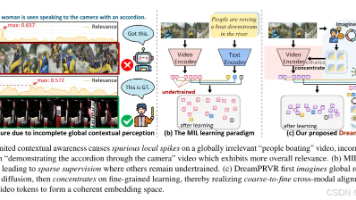
摘要: 哈尔滨工业大学、清华大学等团队提出DreamPRVR模型,解决长视频检索中的"局部尖峰"问题。该模型通过扩散模型想象全局背景,生成语义寄存器,增强局部特征匹配的准确性。采用文本扰动采样和异步注意力机制,显著提升三大数据集(ActivityNet Captions等)的检索性能,同时保持高效推理。代码已开源,为多模态检索提供了新思路。
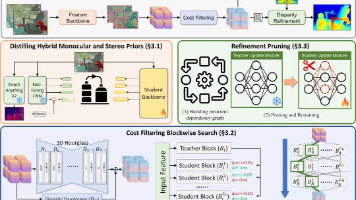
NVIDIA推出Fast-FoundationStereo模型,在保持立体匹配大模型强大零样本泛化能力的同时,通过特征蒸馏、分块架构搜索和结构化剪枝等创新技术,将推理速度提升10倍以上,实现实时运行(47FPS)。该模型在多个基准测试中表现优异,既能媲美顶级泛化模型的精度,又具备实时处理能力,为自动驾驶等实时应用提供了高效解决方案。研究采用了知识蒸馏、互联网级真实数据伪标签等技术,有效解决了合成数