




- @AKAMAI_CHINA
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Akamai应用平台发布,20分钟快速部署生产级Kubernetes环境。该平台预集成了CNCF认证的开源工具链(如Harbor、ArgoCD等),通过GitOps和代码即配置原则实现自动化管理。核心优势包括:1)提供开发者自服务门户和"团队"多租户隔离功能;2)内置"黄金路径"模板库简化应用部署;3)支持从基础设施到应用的端到端自动化配置。特别适合需要快速构建云原生能力的中小企业,同时可作为教育

Gartner预测2025年全球AI支出将达6440亿美元,Forrester最新研究显示76%企业将AI用于改善客户体验。报告基于400位高管的调查,指出个性化服务(53%)、客服自动化(53%)已成为最普遍应用场景,但63%企业仍面临安全挑战。研究建议企业:1)聚焦可量化客户价值;2)平衡创新与治理;3)采用混合架构;4)选择合规伙伴;5)建立实验机制。数据表明,AI成功的关键在于将技术部署与

Akamai Technologies以2.05亿美元完成对浏览器安全公司LayerX的收购。LayerX的平台能增强企业浏览器的安全防护,帮助监控用户与Web内容及SaaS应用的交互。此次收购将整合Akamai的ZeroTrust平台和全球网络优势,为企业提供更全面的员工安全解决方案,特别是在AI应用交互场景。Akamai作为网络安全和云计算公司,致力于通过分布式网络保护全球企业数据。公告包含前

开源AI智能体OpenClaw上线三天获超8万GitHub Star。相较本地部署的高成本与单点风险,Akamai Linode云端方案月费仅$24,15分钟一键部署,通过Telegram等应用即可交互,实现7×24稳定运行、低延迟响应及跨设备无缝访问。

流媒体开源咨询商Eyevinn Technology推出开源云平台,旨在简化开源技术落地。面对部署复杂、全球扩容及安全合规挑战,Eyevinn选择Akamai Cloud作为底层架构,借助其全球分布式算力、K8s托管服务与企业级安全,实现一键部署、低延迟全球访问及成本优化,构建"易用-增长-迭代"的可持续开源生态。

开源AI智能体OpenClaw上线三天获超8万GitHub Star。相较本地部署的高成本与单点风险,Akamai Linode云端方案月费仅$24,15分钟一键部署,通过Telegram等应用即可交互,实现7×24稳定运行、低延迟响应及跨设备无缝访问。
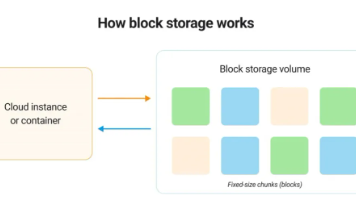
Akamai块存储基于NVMe SSD,提供8000 IOPS与350MB/s吞吐,可突发至12000 IOPS。支持全球分布式部署、全盘加密及擦除编码,保障99.9%可用性。与云实例、K8s无缝集成,支持弹性扩容与热插拔,为数据库及AI负载提供低延迟持久化存储。
开源AI智能体OpenClaw上线三天获超8万GitHub Star。相较本地部署的高成本与单点风险,Akamai Linode云端方案月费仅$24,15分钟一键部署,通过Telegram等应用即可交互,实现7×24稳定运行、低延迟响应及跨设备无缝访问。
技术革命正经历从中心化到去中心化的转变,人工智能也迎来这一关键拐点。当前AI行业过度依赖集中式数据中心模式,导致高延迟、高成本和电力紧张等问题。随着智能代理和自动驾驶等应用的爆发,传统架构已无法满足边缘计算需求。Akamai与NVIDIA合作推出InferenceCloud平台,将AI推理能力延伸至网络边缘,通过缩短数据与用户的距离,实现低延迟、高性价比的实时AI处理。该解决方案标志着云基础设施正

Akamai Cloud基准测试显示,RTX PRO 6000 Blackwell推理吞吐量较H100提升1.63倍,FP4较FP8提升1.32倍。100并发下,单服务器处理能力达24,240 TPS。该GPU以更低功耗、成本和延迟,为分布式AI推理提供高吞吐与高效扩展能力。
